Khanrc
RL - Deep Q-learning
Deep Q-learning
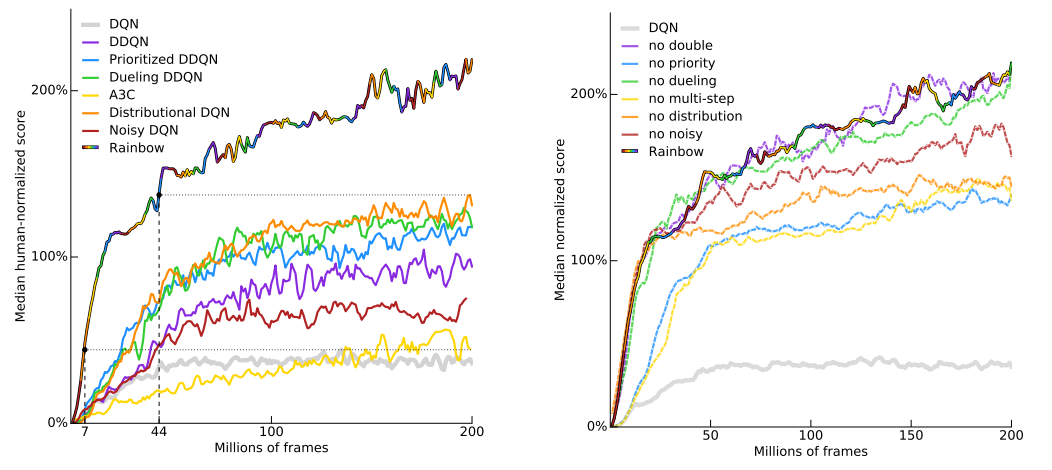
여기서는 Q-learning 에 기반한 알고리즘들을 다루고, 이러한 알고리즘들을 통합적으로 적용하여 성능을 개선한 Rainbow 까지 살펴본다.
DQN
Mnih, Volodymyr, et al. “Human-level control through deep reinforcement learning.” Nature 518.7540 (2015): 529.
- Key idea: Q-learning with deep learning + experience replay + freeze target network
DQN 은 Q-learning 에 function approximator 로 deep learning 을 사용한 버전이다. 딥마인드가 Atari 게임을 풀면서 유명해졌다. Q-learning 에서 Q-function 을 업데이트하는 Loss function 을 다음과 같이 사용한다:
\[L(\theta)=\left( y-Q_\theta(s,a) \right)^2\]그리고 이 때의 target y 는:
\[y=r + \gamma\max_{a'}Q_\theta(s',a')\]다. 이것만으로 잘 되면 좋겠지만 그렇지가 않아서 여기에 몇 가지 트릭을 추가로 사용한다.
Trick 1: Experience replay. RL 에서 데이터는 에이전트가 실제로 움직이면서 얻어내기 때문에, 자연스럽게 데이터 간 correlation 이 심하게 발생한다. 이 문제를 해결하기 위해 experience replay memory 라고 불리는 커다란 데이터 버퍼를 만들고, 다량의 데이터를 쌓아두고 여기서 랜덤하게 샘플링하여 학습에 사용한다. 이는 Q-learning 이 off-policy method 이기 때문에 가능한 방법이다.
Trick 2: Freeze target network. 보통의 supervised learning 과는 다르게, Q-learning 은 parametrized target 을 사용하기 때문에 네트워크를 업데이트 할 때마다 동일한 input 에 대해서도 target 값이 계속 바뀌어서 학습이 불안정해진다. DQN 에서는 학습을 안정화시키기 위해 target 값을 계산하는 Q-network 의 weight 를 고정시키고 일정 주기마다 한번씩 업데이트 해 주는 방식을 사용한다.
DDQN
Van Hasselt, Hado, Arthur Guez, and David Silver. “Deep reinforcement learning with double q-learning.” Thirtieth AAAI Conference on Artificial Intelligence. 2016.
- Key idea: Q-value 가 튀었을 때 그 에러가 바로 퍼지지 않도록 방지책을 두자
Q-learning 이 갖는 고질적인 문제점 중 over-estimation bias 라는 문제가 있다. Q-learning 에서 target 을 계산하기 위해 max 를 사용하기 때문에 발생한다. Stochastic 한 환경에서, 별로 좋은 state 가 아닌데 어쩌다 reward 가 좋게 튀었다고 생각해보자. 이 경우 Q-value 가 바로 좋은 값으로 업데이트되는데, 이 값이 운좋게 얻어걸린 값이라는걸 알기까지 여러번의 추가 방문이 필요하고, 이 동안 이미 이 잘못된 Q-value 가 다른 state 들로 다 전파되어 돌이킬 수 없는 상태가 된다.
이 문제를 해결하기 위해 나온 방법이 double Q-learning 으로, Q-function 을 2개 사용하여 어쩌다 Q-value 가 좋은 값으로 튀더라도 바로 다른 state 들로 전파되지 않게 막는다.
 Pseudo code of double Q-learning
Pseudo code of double Q-learning
위는 서튼책에서 가져온 double Q-learning 의 수도코드다. 이와 같이 Q-function 을 2개 사용하고, 실제로 target 값을 계산하는 Q-function 과 maximum action 을 결정하는 Q-function 을 분리한다. 따라서 두 함수중 하나가 잘못된 값으로 “튀어” 있는 상태더라도 최종적으로 계산되는 target 값은 정상적인 값이 나오게 된다.
Double DQN 은 이 아이디어를 그대로 가져온다. DQN 에서는 freeze target network 를 도입하면서 이미 2개의 네트워크를 사용하고 있으므로, 이를 그대로 사용한다.
\[L(\theta)=\left(r+\gamma Q_{\theta^-}(s',\arg\max_{a'}Q_\theta(s',a'))-Q_\theta(s,a)\right)^2\]$\theta^-$ 는 freezed target network parameter 를 가리킨다.
Dueling DQN
Wang, Ziyu, et al. “Dueling network architectures for deep reinforcement learning.” arXiv preprint arXiv:1511.06581 (2015).
- Key idea: Advantage function A(s,a)
Q-learning 은 어떤 state s 에 대해 각 action a 의 state-action value function Q(s,a) 를 사용한다. 즉, state 가 주어지면 모든 action 에 대해 action value 를 계산해야 한다. 하지만 어차피 같은 state 라면 비슷한 가치를 지닐텐데, 굳이 각 action value 를 따로따로 계산할 필요가 있을까? Dueling DQN 은 Q(s,a) 를 바로 추정하는 대신 V(s) 와 A(s,a) 를 추정하여 Q(s,a) 를 계산하는 방식으로 value function 의 variance 를 잡는다.
\[Q(s,a) = V(s) + A(s,a)\]아래는 이를 위한 네트워크 구조로, V(s) 와 A(s,a) 는 네트워크 파라메터를 상당 부분 공유할 수 있다.
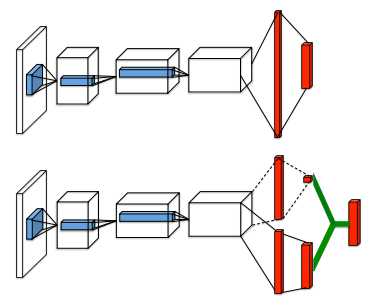 위는 기존 DQN 의 Q-network. 아래는 Dueling DQN. V 와 A 값을 각각 예측하여 Q 를 만들어낸다.
위는 기존 DQN 의 Q-network. 아래는 Dueling DQN. V 와 A 값을 각각 예측하여 Q 를 만들어낸다.
PER
Schaul, Tom, et al. “Prioritized experience replay.” arXiv preprint arXiv:1511.05952 (2015).
- Key idea: 경험에 우선순위를 두자
DQN 에서 도입한 Experience replay 는 모든 경험을 uniform 하게 샘플링한다. 하지만 모든 경험이 같은 가치를 갖지는 않을 터이니, 더 가치있는 경험에 더 가중치를 주면 에이전트가 더 빠르게 학습할 수 있을 것이다. PER 에서는 TD error 로 각 경험의 우선순위를 매기고, 이 우선순위를 기반으로 샘플링을 수행한다.
여기서 생각해 봐야 할 점이 하나 있다. 위 수식에서는 생략했지만 원래 DQN 의 Loss 는 expectation 이다. 즉, expectation 을 sampling 으로 대체하는 것이다. 그런데 이 때 sampling 을 uniform 하게 수행하지 않으면 bias 가 생긴다. PER 은 이 문제를 importance sampling 을 도입하여 해결한다.
C51
Bellemare, Marc G., Will Dabney, and Rémi Munos. “A distributional perspective on reinforcement learning.” Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017.
추천 레퍼런스: RLKorea Distributional RL
- Key idea: value function 이 expectation 값을 예측하는 것이 아니라 분포 자체를 예측하게 하자
당연한 얘기지만, 평균값만 아는 것보다 전체 분포를 다 아는 것이 더 좋다. 평균값에 기반한 추론보다 전체 분포에 기반한 추론이 더 정확할 것이다. 이 관점을 우리가 사용하는 value function 에도 적용해볼 수 있는데, value function 의 output 을 평균값 (expectation 값) scalar 로 하는 것이 아니라 전체 분포 (distribution) 로 하면 된다. 즉, value network 가 어떤 state 의 평균 가치를 예측하는 것이 아니라 가치 분포를 예측하도록 하여 더 정확한 추론을 할 수 있다는 것이다.
Value network 가 분포를 예측하도록 변환하는 건 그리 어렵지 않다. 네트워크의 구조를 바꿔주고, loss 를 계산할 때 결과값이 scalar 가 아니라 분포이므로 KL-divergence 를 사용한다.
마지막으로 target $r+\gamma Q(s,a)$ 만 distributional 하게 바꾸면 된다. 아래 그림을 참고하자. 수식 그대로 연산을 수행하고 처음에 정해놓은 분포 규격으로 맞춰주는 과정을 거친다.
 Adapted from RLKorea Distributional RL - C51
Adapted from RLKorea Distributional RL - C51
이와 같이 scalar-value function 이 아니라 value-distribution function 을 학습함으로써 기존 알고리즘들의 성능을 개선하려는 시도를 distributional RL 이라고 한다. Spinning up 에서는 따로 distributional RL 섹션이 있으나, 한국어로 작성된 좋은 관련 포스팅 (추천 레퍼런스 참조) 이 있기 때문에 여기서는 이 논문만 짚고 넘어간다.
NoisyNet
Fortunato, Meire, et al. “Noisy networks for exploration.” arXiv preprint arXiv:1706.10295 (2017).
- Key idea: Learnable exploration
RL 에서 항상 강조되는 이슈 중 하나가 바로 exploration-exploitation problem 이다. 어떻게 하면 exploration 을 잘할 수 있을 것인지도 주요한 연구 분야중 하나다. 그런데 지금까지 exploration 을 하는 방식을 보면 가장 기본적인 epsilon greedy 방식을 적용하고 있다. 이를 좀 더 잘해볼 수 없을까?
NoisyNet 은 네트워크의 weight 에 perturbation 을 주어 exploration 을 강제한다. 흥미로운 점은 이 perturbation 을 주는 파라메터가 learnable parameter 가는 점이다. 학습 과정에서 이 perturbation 정도가 알아서 조절된다.
보통 네트워크의 최종 output 인 Q-value 를 계산하는 네트워크 마지막 단에는 linear layer 가 붙는다.
\[y=wx+b\]여기에 noise 를 주어 흔들면:
\[y=(\mu^w+\sigma^w \odot \epsilon^w)x + \mu^b+\sigma^b\odot \epsilon^b\]이를 그림으로 표현하면 다음과 같다:
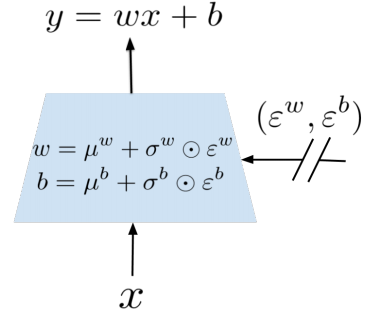
여기서 $\mu$ 와 $\sigma$ 는 learnable parameter 이고, $\epsilon$ 은 학습이 안 되는 noise 에 해당한다.
Rainbow
Hessel, Matteo, et al. “Rainbow: Combining improvements in deep reinforcement learning.” Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
위에서 설명한 6개의 논문을 전부 합치고, 여기에 multi-step learning (n-step TD) 을 적용한 것이 Rainbow 다. Multi-step learning 이란 Q-learning 에서 target 을 계산할 때 원래 1-step bootstrapping 을 하던 것을 n-step bootstrapping 으로 바꾼 것이다:
\[y^{(n)}=r_1+\gamma r_2+...+\gamma^{n-1} r_n+\gamma^n \max_{a'} Q(S_n, a')\]Bootstrapping 이란 value estimation 을 할 때 다른 state 의 estimated value 에 기반하는 것을 말한다.
n-step 을 실제로 진행하여 reward 를 받고, 그 이후의 값은 Q-value 로 대체한다.
Rainbow 에서는 이렇게 7종류의 알고리즘을 사용하여 성능을 개선하였으며, ablation study 를 통해 각각의 알고리즘들이 성능 개선에 기여하고 있음을 보였다.