Khanrc
RL - Meta-RL
Meta-RL
추천 레퍼런스: cs294 - Meta RL slides (Chelsea Finn)
레퍼런스가 따로 달려 있지 않은 슬라이드는 위 추천 레퍼런스에서 가져옴
RL 에이전트는 좋은 정책을 학습하기까지 오랜 시간이 걸리는 데에 반해 사람은 몇번의 trial and error 만으로도 빠르게 학습한다. 사람은 잘 모르는 환경이라도 이전의 경험 속에서 어떻게 행동해야 할 지를 빠르게 찾아내기 때문이다. RL 에이전트도 사람처럼 여러 task 에 대해 경험을 쌓아서 새로운 task 를 만나도 빠르게 학습하고자 하는 것이 meta-RL 이다.
Meta-Learning
추천 레퍼런스: https://lilianweng.github.io/lil-log/2018/11/30/meta-learning.html
Meta-RL 은 RL 에서의 meta-learning 이다. Meta-learning 자체가 생소한 개념인 분들을 위해 간단히 살펴보고 넘어가자. Meta-learning 은 그 자체로 혼동이 쉬운 개념이므로 이 포스트만으로 이해가 안 된다면 위 추천 레퍼런스를 참고하자.
Image classification 문제를 생각해보자. Supervised learning (SL) 은 image x, label y 가 주어졌을 때 적절한 $y=f_\theta(x)$ 함수를 찾는 문제다. Meta-SL 은 어떤 dataset D 가 주어졌을 때 그 dataset 에 대한 $y=f_\theta(x; D)$ 함수를 “빨리” 찾는 문제다. “빨리” 찾아야 한다는 것 말고는 SL 과 meta-SL 의 차이가 없지 않냐는 의문이 든다면 제대로 이해한 것이다. 적은 데이터셋으로도 빨리 학습하고자 하는 것이 meta-learning 의 목표이며, 이를 그대로 RL 로 옮기면 위에서 설명했듯이 새로운 task 에서 적은 trial and error 로도 빨리 학습하는 것이 목표가 된다.
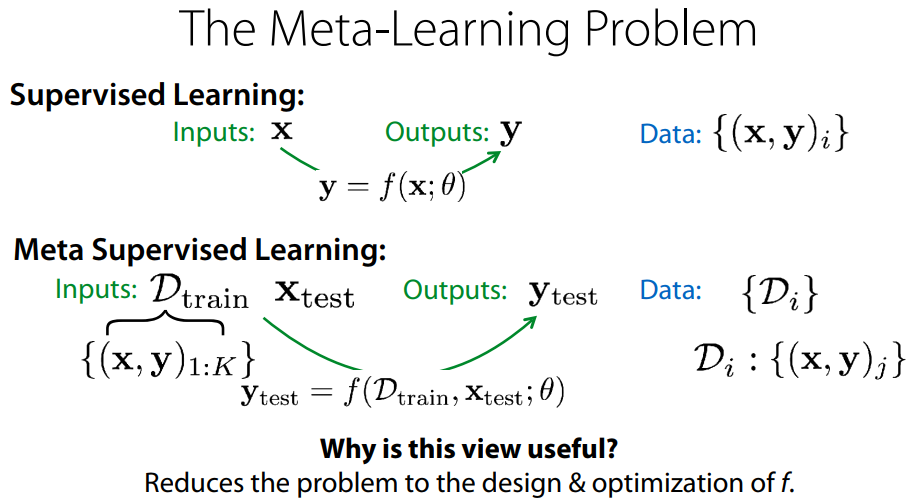
Notation 이 조금 다르지만 위 설명을 한장으로 표현한 것이다. 맨땅에서부터 갑자기 학습을 빨리 할 수는 없으므로, meta-learning task 에서는 대신 meta training dataset 으로 학습한다. SL 에서는 data point 가 이미지 한장이었다면, meta-learning 에서는 data point 가 “작은 데이터셋” 이 된다.
Example: one-shot classification
이해를 돕기 위해 대표적인 meta-learning 문제인 one-shot classification 문제를 보자.
 Adapted from Ravi & Larochelle’17
Adapted from Ravi & Larochelle’17
One-shot classification 은 위 그림과 같이 각 클래스별로 1장의 이미지만 주어지며, 이를 학습하는 것이 목표가 된다. 이렇게 클래스 별 1장씩 총 5장의 training image/label pair 와 2장의 test image/label pair 까지 총 7장의 image와 7개의 label이 모여 하나의 data point 를 이룬다.
Meta-learning 에서는 이와 같이 두 레벨에 걸쳐 training data 와 test data 가 각각 존재하여 혼동이 오기 쉽다. 여기서는 구분을 위해 meta training phase 에서 사용하는 데이터를 meta training data, meta test phase 에서 사용하는 데이터를 meta test data 라고 부른다. 즉, 각 training data 와 test data 는 5개/2개의 이미지로 구성되어 있는 것이고, 이 (training data, test data) pair 가 하나의 meta data point 가 된다.
Basic approach: Fine-tuning (transfer learning)
가장 기본적인 접근법은 주어지는 meta training data 를 통째로 사용해서 그냥 학습시키고, test time 에는 fine-tuning 을 해볼 수 있다. 하지만 아무리 fine-tuning 을 한들 클래스당 1장의 이미지로는 학습이 어렵다. 이를 보다 잘 해보고자 제안된 방법들이 있으며, 이를 metric-based, model-based, optimization-based 의 3종류로 분류할 수 있다.
Metric-based methods
Fine-tuning 다음으로 가장 먼저 생각해 볼 수 있는 접근은 메타 트레이닝 데이터로 모델을 열심히 학습시킨 후 이걸로 feature 를 뽑아서 유사도를 측정하여 kNN (k-nearest neighbor), 즉 가장 유사한 데이터로 매칭하는 방법일 것이다. Metric-based methods 는 이를 위해 어떻게 유사도를 잘 측정할 것인가 라는 관점에서 접근하는 방법들이다.
Model-based methods
문제를 통째로 모델에게 던져서 해결해보려는 접근도 있다. 너무 적은 데이터로 학습이 어려우니까 이를 우회하는 접근이 metric-based methods 였다면, model-based methods 는 그냥 이 적은 데이터로 학습을 해야 하는 meta-learning task 자체를 통째로 모델에게 던진다. 애초에 $y=f_\theta(x; D)$ 를 찾는 것이 목표였으니, training data D 를 따로 학습용으로 사용하는 것이 아니라 그냥 모델에게 던져서 모델이 알아서 재주껏 사용하도록 하는 것이다. 즉, $y=f_\theta(x, D)$ 로 모델링한다.
이러한 방식에 사람의 inductive bias 를 조금 넣어보면, 메모리를 갖는 모델이 좋을 것이라고 생각의 흐름이 자연스럽게 이어진다. Memory model 을 사용하면 metric-based 방법론에서 kNN 부분까지 통째로 모델링이 가능하다. Meta test phase 에서 트레이닝 데이터가 들어오면 모델이 알아서 데이터를 잘 저장하고, 테스트 데이터가 들어오면 알아서 잘 유사도를 계산하고 가장 가까운 클래스를 찾아내기를 기대한다. 이러한 model-based methods 에는 external memory 를 사용하는 Memory-Augmented Neural Networks (MANN) 계열과 internal memory 를 사용하는 RNN 계열이 있다.
Optimization-based methods
Optimization-based methods 계열은 meta test phase 에서 training data 를 이용하여 optimization 을 수행한다. 하지만 위에서 이야기했듯 적은 데이터로 overfitting 을 피하면서 optimum 을 찾으려면 scratch 부터 gradient descent (GD) 로 학습하는 기존의 방식은 어려움이 있다. 크게 두 가지 접근이 있는데, 1) GD 를 대체하는 optimizer 를 학습하는 방법과 2) scratch 부터 학습하지 않고 적은 GD step 으로 optimum 을 찾을 수 있는 initial weights 를 찾는 방법이 있다.
Basic approach 로 소개했던 fine-tuning 도 사실 optimization-based methods 에 속한다고 할 수 있다.
Back to the RL problem
지금까지 meta-learning problem 을 one-shot learning 을 예로 들어 SL 태스크에서 설명했지만, 그대로 RL 태스크에도 적용이 가능하다.

앞서 SL 이 $y=f_\theta(x)$ 를 찾는 문제라면, meta-SL 은 $y=f_\theta(x; D)$ 를 “빨리” 찾는 문제라고 했었다. 이를 RL 에 대입하면, RL 은 $a=\pi_\theta(s)$ 를 찾는 문제고, meta-RL 은 $a=\pi_\theta(s; D)$ 를 마찬가지로 “빨리” 찾는 문제가 된다. SL 에서의 data point (x, y) pair 는 RL 에서는 한번의 experience (s, a, r, s’) 이 된다. SL 에서는 클래스 별로 하나씩 이미지를 주고 학습하라는 것이 챌린지였다면, RL 에서는 환경에 대해 1회의 trial 만으로 학습하는 것이 챌린지가 되는 식이다.
RL^2
Duan, Yan, et al. “RL $^ 2$: Fast Reinforcement Learning via Slow Reinforcement Learning.” arXiv preprint arXiv:1611.02779 (2016).
- Key idea: Model-based meta-RL
RL^2 는 model-based meta-RL 이다. Meta training 시에 다양한 environment 에 대한 interaction 을 통해 general 한 interpretation 을 얻고, 이를 사용하여 적은 수의 trial 만으로도 새로운 environment 를 학습할 수 있다. 이를 위해 internal memory 를 갖는 RNN 기반 모델을 사용하고, 단 2회의 에피소드동안 return 을 maximize 하도록 디자인한다.
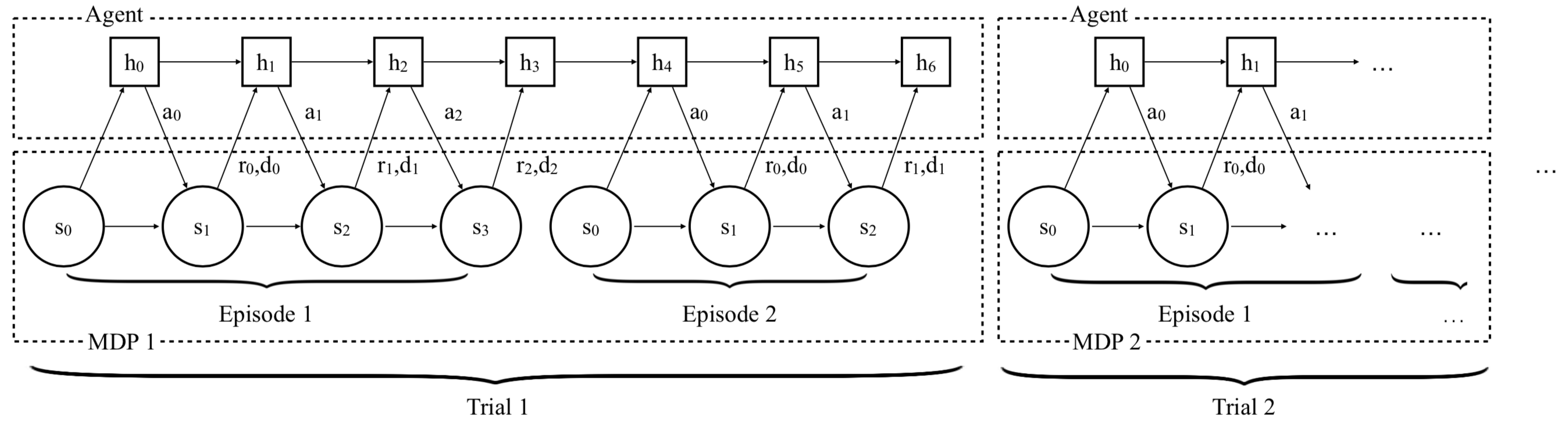 RL^2 agent-environment interaction overview
RL^2 agent-environment interaction overview
RL^2 에서는 위와 같이 2 episode 를 1 trial 이라 부른다. Meta-RL problem 이므로 한번의 trial 이 끝나면 다음 trial 에서는 새로운 environment 로 변하고, 따라서 RNN hidden state 도 이어서 가져가지 않고 초기화하는 방식으로 구성된다. 여기에 한번의 trial 에서 얻는 return 을 maximize 하도록 학습하므로, RNN 모델은 2번의 episode 만에 “빨리” 학습하는 법을 배운다. RNN 모델로는 GRU 를 사용하였고, 학습에는 TRPO 와 더불어 GAE 를 적용하였다.
SNAIL
Mishra, Nikhil, et al. “A simple neural attentive meta-learner.” arXiv preprint arXiv:1707.03141 (2017).
추천 레퍼런스: PR12-153: SNAIL
- Key idea: RL^2 + advanced temporal dependency design
Long-term dependency 를 모델링하기 위해서 제안된 RNN 은 생각보다 long-term dependency 를 그리 잘 잡아내지 못한다. 그 때문에 LSTM 이 제안되었지만, LSTM 조차도 long-term dependency 를 잘 잡아내지 못한다는 것이 근래에 밝혀졌다. 그래서 최근에는 아예 이러한 sequential model 을 사용하지 않고, 보다 직접적인 long-term connection 을 사용하는 방법들이 제안되었다. 대표적으로 Transformer 에서 사용한 self-attention 이나 WaveNet 에서 사용한 temporal causal convolution 등이 있다. 이와 같은 네트워크 모델링에서의 recent advances 들을 RL^2 에 더한 것이 Simple Neural Attentive Learner (SNAIL) 다.
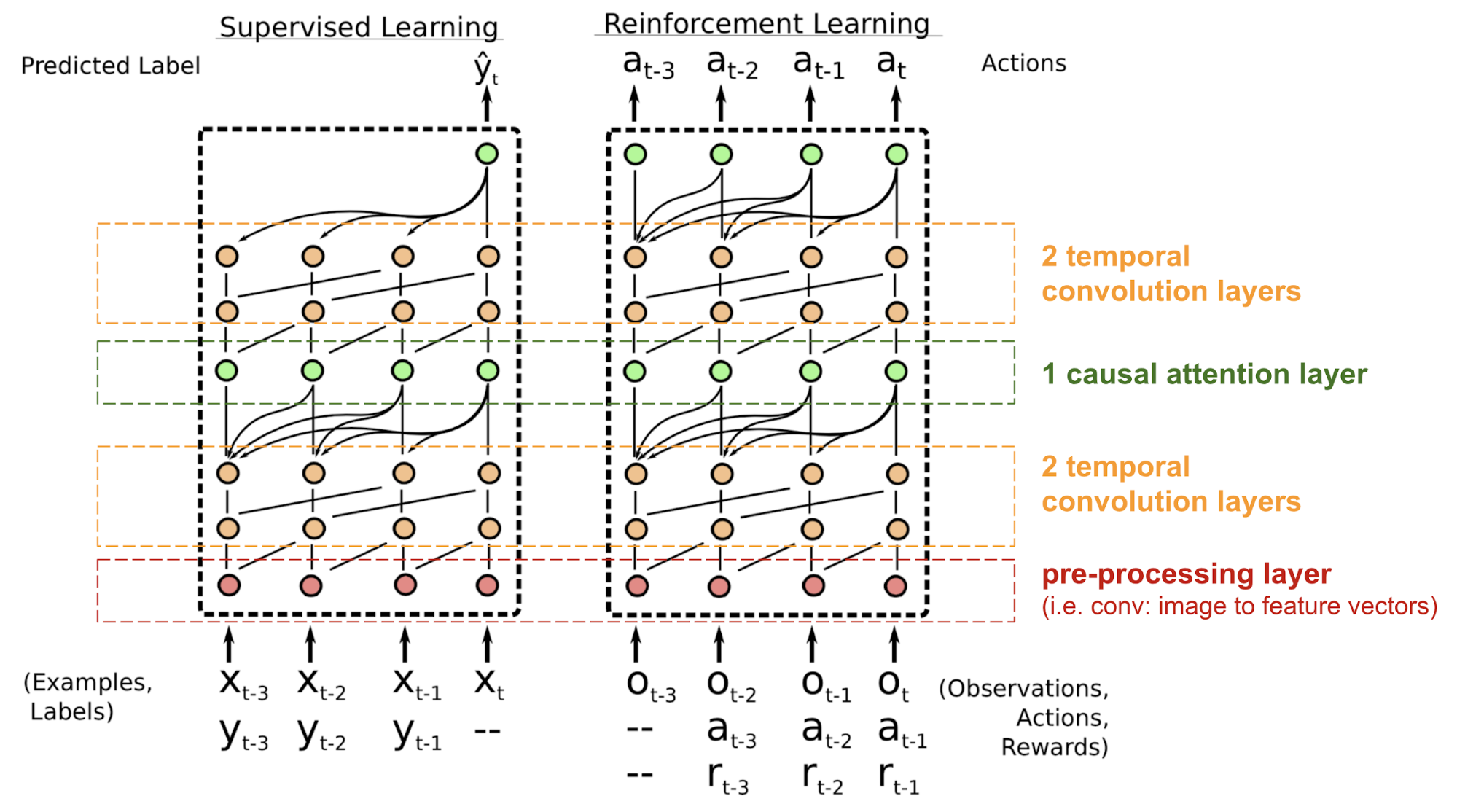 Adapted from Mishra et al., 2017
Adapted from Mishra et al., 2017
위 그림과 같이 RNN 을 사용하지 않으며, 대신 temporal causal convolution (주황색) 과 self-attention (초록색) 을 같이 사용하였다. Temporal causal convolution 은 temporal dependency 를 잡기 위해 디자인되어 temporal 이 붙었고, 일반적인 conv 와 다르게 시간축 기준으로 미래 정보는 사용하지 않기 때문에 causal 이 붙었다.
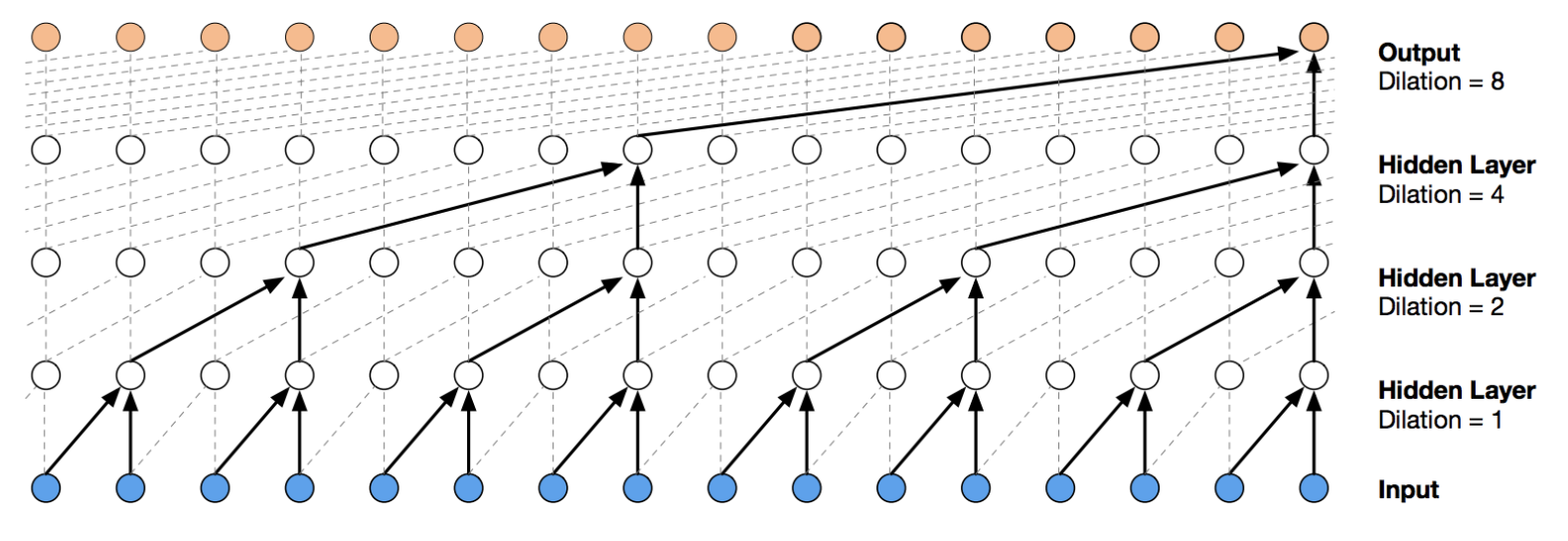 Adapted from WaveNet
Adapted from WaveNet
그리고 정확히 말하면 위와 같이 dialted convolution 이므로 temporal causal dialted convolution 이다. 이를 SNAIL 에서는 TC block 이라고 한다. Attention 또한 마찬가지로 미래 정보를 보지 못하도록 디자인하여 논문에서는 causal attention 이라고 부르기도 한다.
최종적인 학습 알고리즘은 RL^2 와 마찬가지로 TRPO 에 GAE 를 더해 사용하였다.
MAML
Finn, Chelsea, Pieter Abbeel, and Sergey Levine. “Model-agnostic meta-learning for fast adaptation of deep networks.” Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017.
추천 레퍼런스: PR12-094: MAML
- Key idea: 적은 수의 데이터로 fine-tuning 을 해야 한다면, 처음부터 “적은 수의 데이터로 fine-tuning 을 했을 때 optimum 으로 가도록” 하는 objective function 을 사용하자!
Model-Agnostic Meta-Learning (MAML) 은 기본적으로 pre-training 을 잘 해보자는 관점이다. 앞서 fine-tuning 을 한다고 해도 너무 적은 데이터로는 어렵다는 이야기를 했었다. 하지만 적은 데이터로도 fine-tuning 이 가능하게 하는 좋은 pre-trained weights 가 어딘가엔 존재하지 않을까? 이러한 관점으로부터, 어차피 나중에 fine-tuning 을 할 것이니 이것까지 고려하여 pre-training 하는 것이 MAML 의 접근이다.
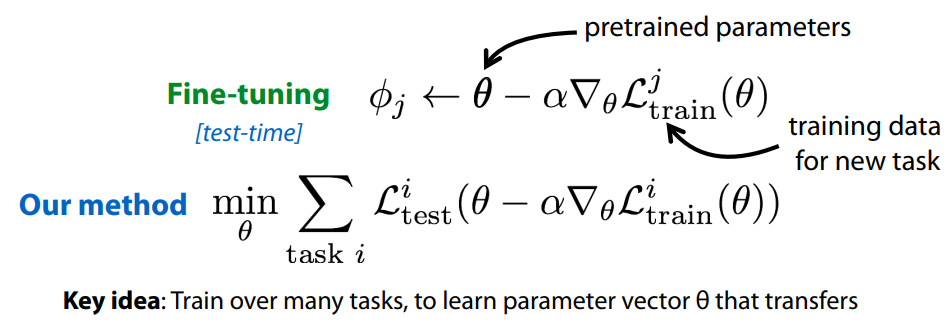
Fine-tuning 이 한번의 step 으로 이루어진다고 해 보자. 그러면 task j 에 대한 fine-tuned parameter $\phi_j$ 는 위와 같이 구할 수 있다. 우리가 pre-training 을 할 때 정확히 하고 싶은 것은 현재 데이터에 대한 optimum 을 구하는 것이 아니라 추후 fine-tuning 을 했을 때 optimum 으로 가는 것이다. 따라서 처음부터 fine-tuning 을 할 것을 감안하여 pre-training objective function 을 디자인 한 것이 바로 MAML 이다.