Khanrc
RL - Transfer and Multitask RL
Transfer and Multitask RL
추천 레퍼런스: cs294 - Transfer and Multitask RL slides (Sergey Levine)
Supervised Learning (SL) 에서의 transfer learning 이나 multitask learning 의 개념을 RL 에도 적용할 수 있다. 어떤 환경에서 학습한 policy/value, feature extractor 등을 다른 환경에 가져다 활용하는 transfer RL 이라던가, 각종 Atari 2600 game 들에서 general 하게 잘 작동하는 multitask RL 도 가능하며, 새로운 task 를 만났을 때 빠르게 학습할 수 있도록 도와주는 meta-learner 를 도입하여 meta RL 까지도 확장된다. 이러한 multitask learning 은 여러 태스크에 대해 잘 작동하는 인공지능을 의미하기 때문에 Artificial General Intelligence (AGI) 와도 맞닿아 있다.
HER
Andrychowicz, Marcin, et al. “Hindsight experience replay.” Advances in Neural Information Processing Systems. 2017.
- Key idea: 사람처럼 RL agent 도 실패로부터도 배우자.
- Key intuition: 실제로 goal 을 달성하지 못했더라도 reward 를 주어, 적극적으로 움직이는 agent 를 만들면 결국 실제 goal 을 달성할 수 있다.
HER 은 사실 sparse reward problem 을 풀기 위해 multitask method 를 활용하는 방법이지 transfer 혹은 multitask problem 을 풀기 위해 제안된 방법이 아니다. 다만 다른 카테고리에 넣기에도 애매한 부분이 있어서 spinning up 에서 분류한 그대로 transfer and multitask RL 카테고리에 넣었다. 개인적으로는 random intrinsic reward 에 의한 exploration 방법론에 가깝다고 생각한다.
Hindsight Experience Replay (HER) 은 매우 재미있는 방법론이다. 사람과 RL의 학습 방법 중 주요한 차이 중 하나는, 사람은 실패로부터도 배우지만 RL agent 는 성공으로부터만 배운다는 것이다. 하키에서 공을 골대에 넣는 연습을 한다고 생각해보자. 공을 쳤는데 파워는 훌륭하지만 방향이 잘못되었을 경우, 사람은 방향만 잘 조절하면 되겠다고 생각하지만, agent 에게는 그저 실패인 경험으로 남는다.
RL 에서도 이렇게 실패로부터도 배우게 하고 싶다면 domain knowledge 를 통해 reward 를 가공하는 방법이 있다. 공의 파워와 방향을 분리하여 둘중 하나가 맞았다면 골대에 들어가지 않았더라도 약간의 reward 를 주는 방식이다. 이를 reward engineering 혹은 reward shaping 이라고 부르며, sparse reward 를 dense reward 로 바꿔준다. 문제는 이 작업이 매우 domain specific 하고 까다로운 작업이기 때문에 이러한 reward engineering 없이 sparse reward problem 을 푸는 것이 RL 의 주요한 챌린지가 되며, 앞선 포스트들에서도 그러한 알고리즘들을 살펴보았다.
HER 에서도 마찬가지로 이러한 sparse reward problem 을 다루는데, 까다로운 reward engineering 없이도 실패로부터도 배우도록 한다. 마치 마법같은 이야기이지만 방법은 매우 간단하다. Agent 가 timestep T 이후에 goal $g$ 에 도달하지 못했더라도, final state $s_T$ 가 마치 goal 인 것처럼 reward 를 준다. 이렇게 되면 agent 는 goal 로 가는 방법은 아니더라도 $s_T$ 로 가는 방법은 배우게 되므로, 이후에 random policy 에 비해 더 많은 곳을 가볼 수 있게 되어, 최종적으로 언젠가 goal 에 도달할 수 있게 해 준다.
 HER pseudo code
HER pseudo code
모든 final state 를 goal 로 취급하면 실제 goal 과 구분이 안 되므로, 일부 final state 만 랜덤하게 sampling 하여 goal 로 취급하고, goal 로 취급하기 전의 original trajectory 도 함께 experience replay 에 넣음으로써 실제 goal 의 경우 보다 높은 리워드를 받을 수 있게 해 준다.
HER 은 experience replay 방법론이므로 DQN 이나 DDPG 등 다양한 off-policy method 와 함께 사용할 수 있다.
Intuitive explanation
논문에서 하키 예시를 들었기 때문에 위에서도 하키 이야기를 했지만, 사실 HER 의 학습 방식이 하키 예시와 들어맞지는 않는다. 사람은 general intelligence (혹은 prior knowledge) 가 있기 때문에 실패를 분석하여 학습이 가능하지만, general intelligence 가 없는 HER 은 그렇게 할 수 없다.
HER 의 학습 방식은 아이에게 해주는 격려와도 같다. 상황을 분석해서 학습을 하는 것은 아니지만, reward 를 받을 수 없는 부정적인 환경 속에서 정말로 잘했고 못했고를 떠나서 지속적인 격려를 해줌으로써 적극적인 에이전트를 만들어준다. 이 격려는 실패를 분석한 격려가 아니기 때문에 잘못된 방향으로 빠질 수도 있지만, 어차피 랜덤한 방향으로 격려를 해주는 것이기 때문에 시간이 지나면 언젠가 올바른 방향으로 갈 것이고 true reward 를 획득할 수 있을 것이다.
PathNet
Fernando, Chrisantha, et al. “Pathnet: Evolution channels gradient descent in super neural networks.” arXiv preprint arXiv:1701.08734 (2017).
- Key idea: 어떤 task 를 전체 파라메터중 일부에 해당하는 특정 pathway 만을 사용해서 학습시키고, 다른 task 에 대해 이 pathway 는 고정한 채 나머지 파라메터만 학습시키는 transfer learning method 제안
PathNet 은 AGI 를 표방하며 유명해진 논문이다. 일반적인 transfer learning 이 학습된 네트워크를 가져다가 fine-tuning 을 한다면, PathNet 은 처음부터 transfer learning 을 위해 전체 파라메터를 전부 학습시키는 것이 아니라 일부에 해당하는 특정 pathway 만을 학습시킨다.
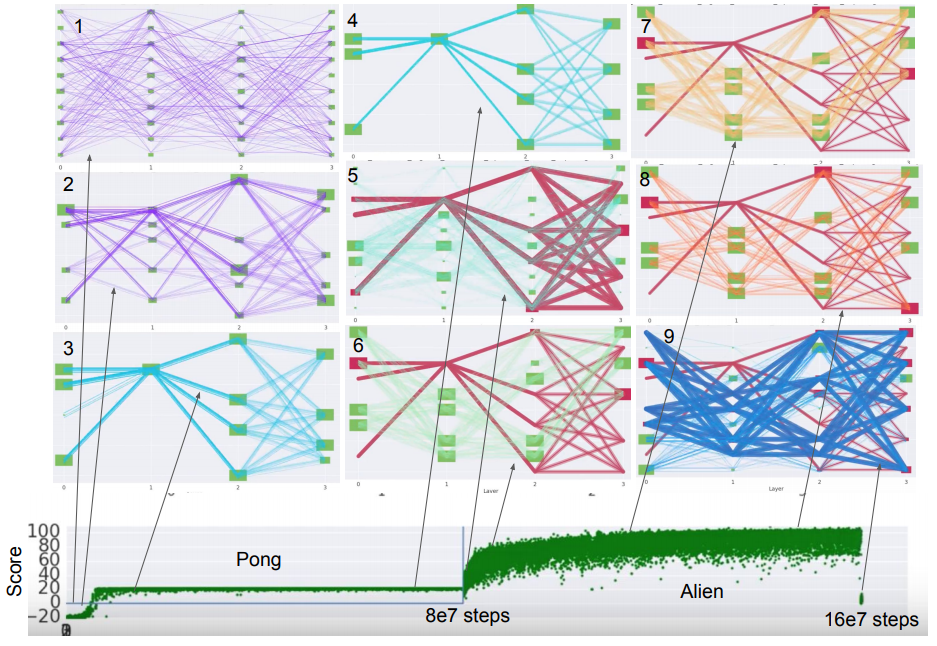 PathNet training progress
PathNet training progress
위 그림은 PathNet 의 학습 과정을 잘 보여준다. 1번 그림은 random initialized 된 상태이고, 학습이 계속 진행되면서 Pong task 를 풀기 위한 pathway 들만 하이라이트되어 4번 그림에서는 일부 pathway 만이 보인다. 그리고 5번 그림은 Alien task 에 들어가는 시점이고, 이 때 이전 task 에서 찾은 pathway 는 고정한다 (빨간 선). 그 이후 나머지 pathway 들만 학습을 진행하면 Pong task 에서 학습한 pathway 를 기반으로 transfer learning 이 가능하다.
각 task 를 위한 pathway 는 genetic algorithm (GA) 을 통해 학습한다. A3C 를 사용해서 64개의 후보 pathway 를 동시에 학습시키고, 가장 return 이 좋은 pathway 를 뽑아서 사용한다. 그리고 그 pathway 를 기반으로 다시 mutation 을 통해 64개의 후보 pathway 를 생성해내는 과정을 반복한다.
사실 PathNet 은 그 유명세나 AGI 를 표방하는 것에 비해, 방법은 신선하지만 결과는 그다지 특별할 것이 없다. 그 때문인지 2017년 초에 처음 아카이브에 올라왔지만 이후에 어떤 학회나 저널에서 발표되지는 않은 것으로 보인다.