Khanrc
AutoML (1) - Introduction
Overview
본 글은 총 5개의 포스트로 구성되며, 첫번째 포스트에서는 AutoML 과 Neural Architecture Search (NAS) 의 여러 알고리즘들을 다룬다. 그리고 나머지 4개의 포스트에서는 개인적으로 인상깊게 읽은 논문인 DARTS: Differentiable Architecture Search 에 대해서 이론과 코드를 자세히 설명하고, 이를 multi-gpu 까지 확장한다.
AutoML
AutoML 은 Automated Machine Learning 의 약자로, 말 그대로 머신러닝의 자동화에 대한 분야다. 머신러닝으로 문제를 푼다고 할 때 그 과정을 자동화하는 것을 목표로 하며, 하이퍼파라메터 서치가 대표적인 케이스다. 딥러닝이 대세로 자리잡은 이후로 단순히 하이퍼파라메터를 최적화하는 것이 아니라 네트워크 구조를 자동으로 찾아주는 방법에 대한 필요성이 커졌으며, 이것이 바로 최근에 주목받고 있는 Neural Architecture Search (NAS) 다.
이 글에서는 NAS 의 주요 논문들에 대해 간단하게 살펴보고, 개인적으로 가장 흥미롭게 읽은 논문인 DARTS 에 대해 자세히 살펴본다.
Problem setting
NAS 를 포함하여 AutoML 은 최적화 문제다. 어떤 네트워크 구조를 사용할 지, 어떤 하이퍼파라메터를 사용할 지 등을 search space 로 갖고, 거기서 validation loss 혹은 accuracy 등을 objective function 으로 갖는다. 그럼 이제 이 서치 스페이스를 잘 탐색하여 objective function 을 잘 최적화하면 되는 문제다.
그렇다면 이 문제 정의로부터 연구의 방향도 생각해 볼 수 있다. 1) 서치 스페이스를 어떻게 정의하느냐 2) 어떤 최적화 알고리즘으로 이 서치 스페이스를 탐색하느냐 3) objective function 을 어떻게 정의하느냐 4) objective function 을 어떻게 계산하느냐. 여기서 4번이 좀 생소하게 느껴질 수 있는데, 이는 objective function 의 값을 계산하기가 어려운 AutoML 의 문제적 특성 때문에 발생한다. objective function 을 validation accuracy 로 정의했다면, 이 값을 계산하기 위해서는 네트워크를 통째로 학습하여 그 결과를 확인해야 하므로 엄청난 계산량이 요구된다. 따라서 AutoML 에서는 이 objective function 을 어떻게 빨리 계산할 수 있을지도 주요한 챌린지가 되는 것이다.
Categorized by optimization methods
NAS 논문들을 다양한 관점에서 분류할 수 있겠지만, 여기서는 어떤 최적화 방법을 사용했는지에 따라 나누어 설명한다. 기본적으로 NAS 에서 주로 사용하는 objective function 인 validation accuracy 가 non-differentiable objective function 이기 때문에 objective function 의 gradient 를 직접적으로 사용하지 않는 방법들이 주를 이룬다. 이 글에서는 각 최적화 방법론에 대한 설명은 따로 하지 않으며 어느정도 알고 있다고 가정한다.
이 글에서는 네트워크 구조에 대한 gradient 를 사용하는 경우만 gradient-based method 라고 부른다. 즉, RL 기반 방법론에서 사용하는 gradient 는 controller parameter 에 대한 gradient 이기 때문에 여기서는 gradient-based method 라 하면 RL 은 포함되지 않는다.
참고로, 아래 논문들의 약어는 대부분 논문에서 제안한 약어이나 NASRL 과 TNAS 는 따로 제안한 약어가 없어 임의로 정하였다. AmeobaNet 과 AutoKeras 는 각 논문의 산출물의 이름인데 이를 약어로 사용한다.
또한 대부분의 논문들이 CNN 과 함께 RNN 에 적용한 결과도 보이나, 본 글에서는 CNN 구조를 찾는 방법에 집중한다. RNN 도 디테일한 부분이 달라질 뿐 큰 부분에서는 동일하다.
- Reinforcement learning (RL)
- NASRL. Zoph, Barret, and Quoc V. Le. “Neural architecture search with reinforcement learning.” arXiv preprint arXiv:1611.01578 (2016).
- TNAS. Zoph, Barret, et al. “Learning transferable architectures for scalable image recognition.” arXiv preprint arXiv:1707.07012 2.6 (2017).
- ENAS. Pham, Hieu, et al. “Efficient Neural Architecture Search via Parameter Sharing.” arXiv preprint arXiv:1802.03268 (2018).
- MNAS. Tan, Mingxing, et al. “Mnasnet: Platform-aware neural architecture search for mobile.” arXiv preprint arXiv:1807.11626(2018).
- Evolutionary algorithms (EA)
- AmeobaNet. Real, Esteban, et al. “Regularized evolution for image classifier architecture search.” arXiv preprint arXiv:1802.01548 (2018).
- Bayesian optimization (BO)
- AutoKeras. Jin, Haifeng, Qingquan Song, and Xia Hu. “Efficient neural architecture search with network morphism.” arXiv preprint arXiv:1806.10282 (2018).
- Sequential model-based optimization (SMBO)
- PNAS. Liu, Chenxi, et al. “Progressive neural architecture search.” arXiv preprint arXiv:1712.00559 (2017).
- Gradient descent (GD)
- DARTS. Liu, Hanxiao, Karen Simonyan, and Yiming Yang. “Darts: Differentiable architecture search.” arXiv preprint arXiv:1806.09055 (2018).
Reinforcement Learning
RL 기반 방법론들은 validation accuracy 를 reward 로 보고, 네트워크의 각 파트들을 action 으로 본다. 여러번의 action 을 통해 네트워크를 정의하고 나면 학습을 통해 reward 를 얻을 수 있으며, 이 값으로 action 을 생성하는 policy 를 학습한다. State 는 각 시점까지 완성된 네트워크의 구조라고 할 수 있으나, 이를 명시적으로 사용하지 않고 policy 를 RNN 으로 디자인함으로써 implicit 하게 가져간다. 이러한 policy RNN 을 controller 라고 하며, 컨트롤러가 생성한 네트워크의 구조를 child network 라 부른다.
NASRL
NAS 를 널리 알린 첫 논문. 첫 논문인 만큼 서치 스페이스 디자인이나 셀 디자인 등 전체적인 디자인이 꽤나 둔탁하다.
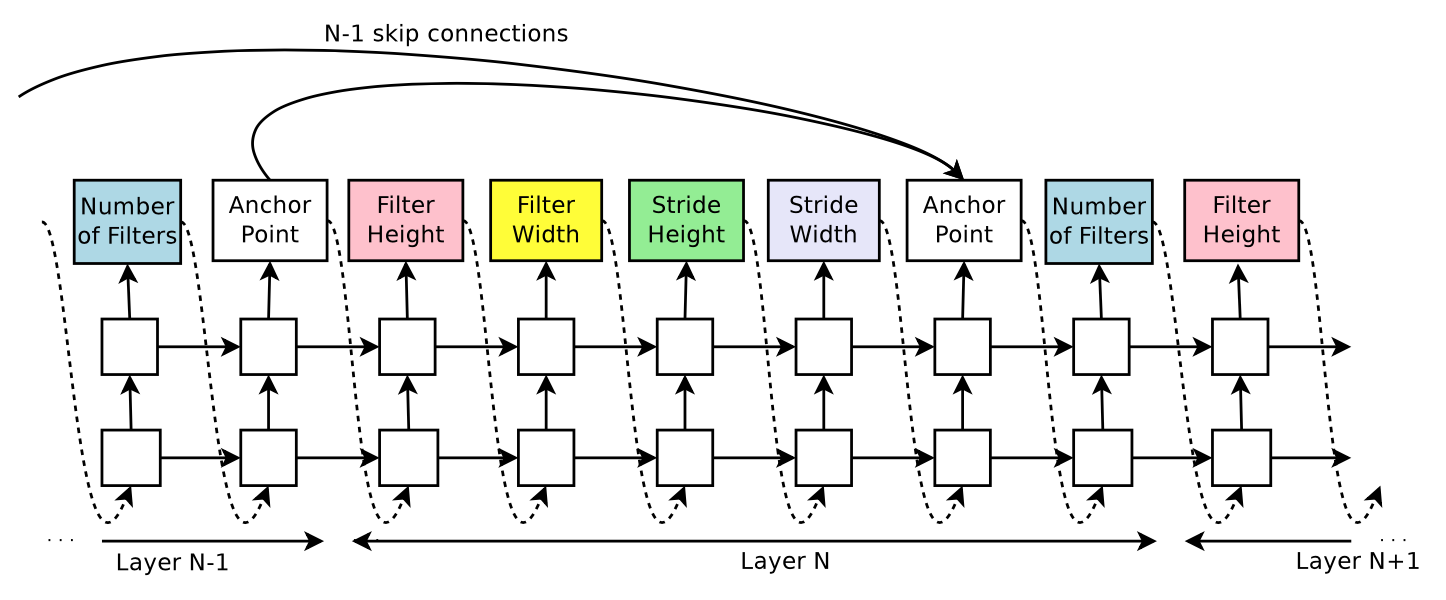
이러한 RNN controller 가 레이어 각각의 convolution 연산의 특성과, skip-connection 을 어떤 레이어로 연결할지 결정한다. skip-connection 은 어텐션 구조를 활용하여 결정하는데, softmax 가 아니라 sigmoid 로 결정하기 때문에 여러 레이어에 skip-connection 이 가능하다. 참고로 레이어 수는 가변이 아니며 하이퍼파라메터로 정해준다.

그 결과로 얻어지는 게 위와 같은 괴랄한 구조인데, 흥미로운 점은 이게 적어도 local optimum 이라는 것이다. 논문에서는 이 구조에 skip connection 을 더하거나 빼서 실험을 해 보았으나 결과가 나빠졌다고 보고하고 있다.
TNAS
전체 네트워크를 다 디자인하는 것이 아니라, 셀 구조를 찾아서 스택하는 방식을 적용하였다. 또한 작은 데이터셋 (CIFAR-10) 에서 셀 구조를 찾고, 이 셀을 더 스택하여 큰 데이터셋 (ImageNet) 에 적용하는 방식을 제안. 이러한 방식을 통해 ImageNet 에서 SOTA 를 찍었다.
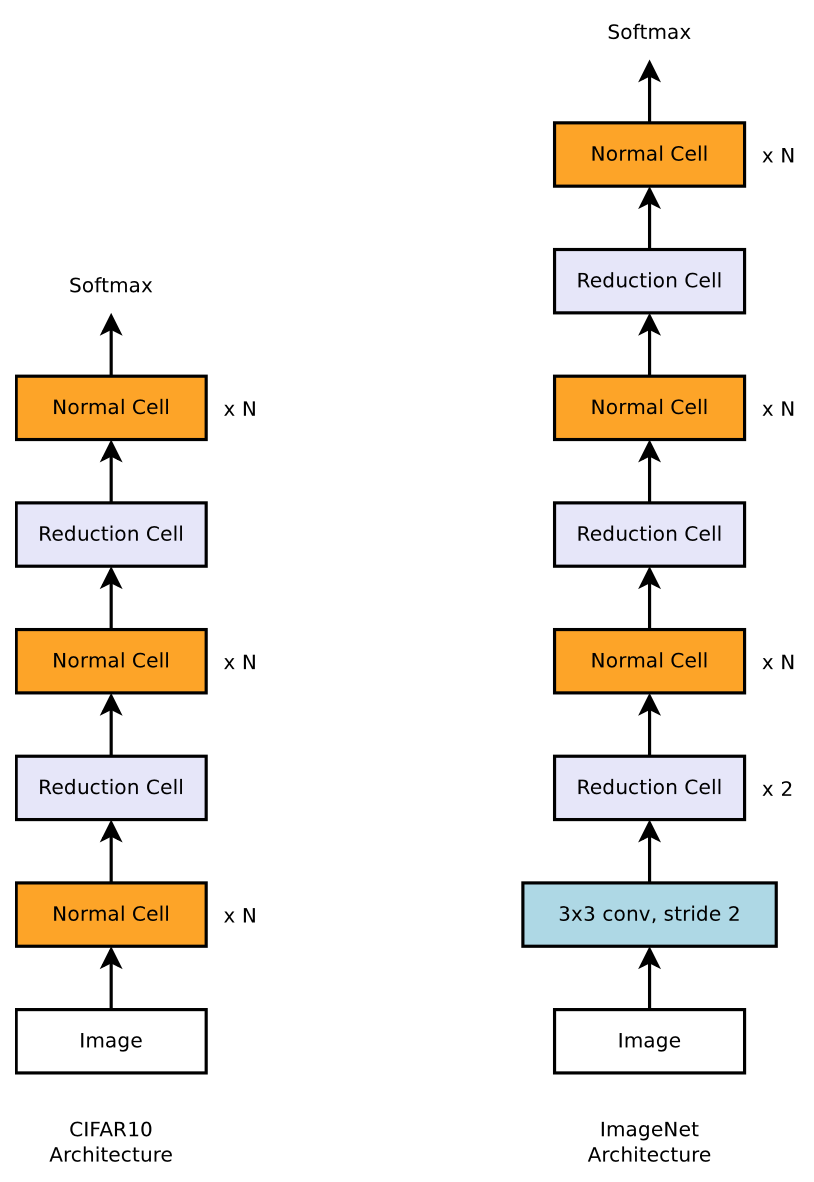
위와 같이 CIFAR10 에 대해 Normal cell 과 featuremap size 를 줄이는 Reduction cell 을 각각 찾은 뒤 그대로 ImageNet 에 적용한다. ImageNet 에 적용할 때에는 셀을 스택하는 횟수 N 과 채널 사이즈 C 는 재조정한다.
이 논문은 NAS 에 필요한 디테일한 부분들을 많이 정립했다. 셀 디자인과 서치 스페이스를 새로이 정의하며, 여기서 정의한 구조와 다양한 테크닉들은 이후 논문들에서도 계속 사용된다.
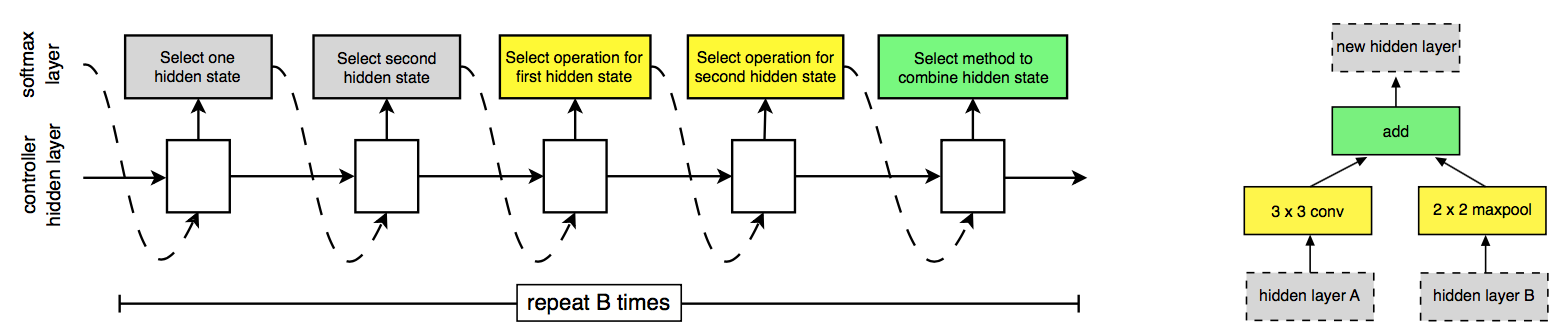
NASRL 과는 다르게 skip-connection 을 2개로 고정하며, operation 또한 이전처럼 filter size 와 stride size 를 찾는 것이 아니라 자주 쓰이는 operation 들을 후보로 놓고 그 안에서 탐색한다:

이렇게 2개의 input 을 받아서 각각 연산을 한 후 combine 연산을 통해 합쳐지는 것을 하나의 블럭이라고 하는데, 이러한 블럭들이 모여 하나의 셀을 이룬다. 이러한 형태의 블럭 구조를 사용함으로써 시퀀셜한 구조였던 NASRL 과 달리 네트워크 구조에 topology 를 가할 수 있다.
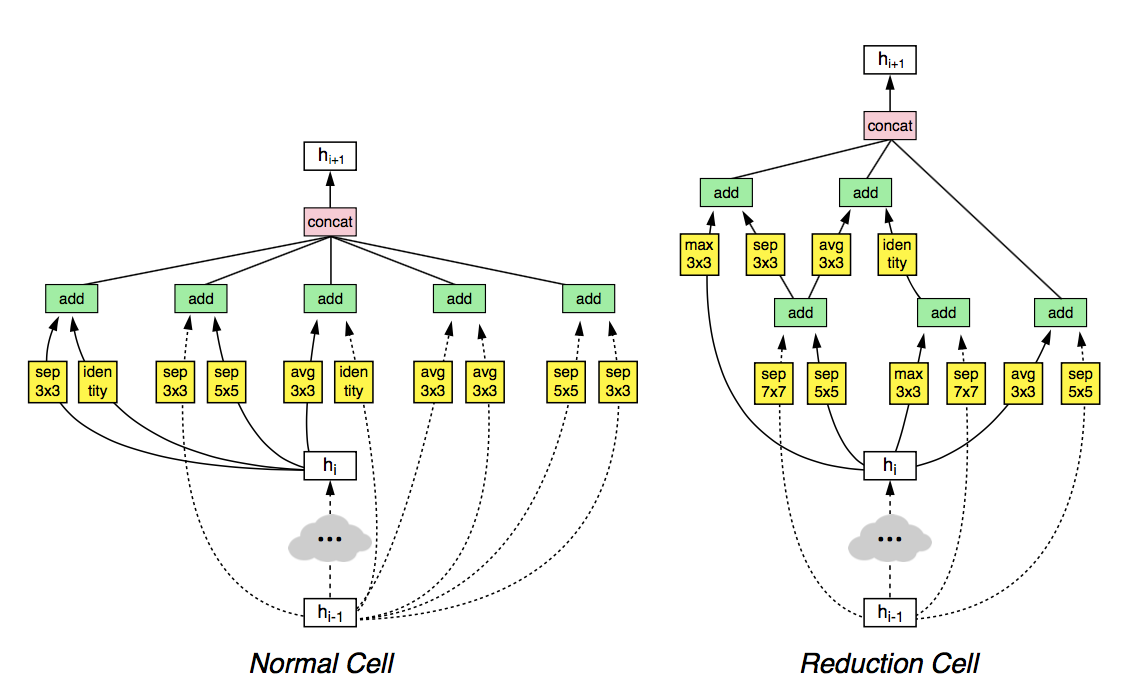
위 그림은 이러한 방식으로 찾은 NASNet-A 의 셀 구조이며, 이렇게 두 종류의 셀을 찾으면 이를 스택하여 큰 데이터셋에 적용할 수 있다.
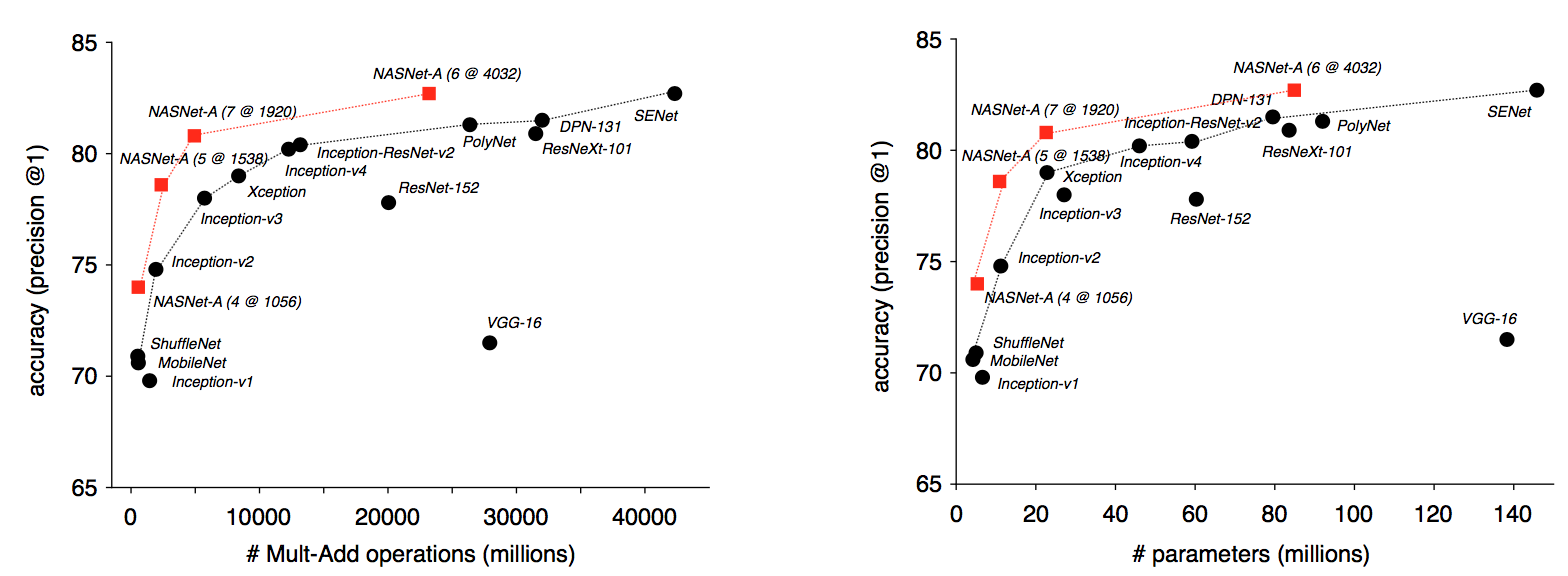
이렇게 찾은 NASNet 구조는 ImageNet 에서 SOTA 를 찍었으며, 이후로도 이 이상의 큰 성능향상은 찾아보기 어렵다.
ENAS
NASRL 과 TNAS 를 포함하여 ENAS 이전까지의 NAS 는 대부분 어마어마한 양의 컴퓨테이션 리소스가 소모되었다. gpu days 라는 단위를 사용하는데, 1개의 gpu 를 사용한다고 했을 때 며칠이 걸리는지를 나타내는 단위다. 이게 ENAS 이전의 논문들은 수백 혹은 수천에 이른다 (심지어 NASRL은 만 단위다) - 따라서 gpu 하나만 가지로 학습한다고 하면 최소한 3년 이상이 걸린다는 것이다! ENAS 에서는 이를 줄이기 위한 여러가지 효율적인 테크닉들을 제안하고, 이를 통해 이 수천에 이르던 필요 리소스를 0.5 gpu day 로 줄여 버린다.
이를 위해 parameter sharing 이라는 아이디어를 제안하는데, 그 방법이 꽤나 재미있다. 위치와 인풋과 연산이 동일하다면 서로 parameter 를 공유한다. 즉 동일한 위치에서 동일한 인풋을 받고 동일한 연산을 한다면, 네트워크의 다른 부분이 어떻게 생겨먹었든 동일한 파라메터를 사용한다!

예를 들어, 위와 같은 directed acyclic graph (DAG) 구조의 search space representation 을 사용한다고 해 보자. 위 그림은 RNN cell architecture search 그림이다. 각 노드는 activation function 을 의미하고, 각 엣지는 input node 를 의미한다. 즉 2번 노드는 ReLU activation 을 사용하고, 1번 노드의 아웃풋을 인풋으로 받는다. RNN cell 이기 때문에 연산은 무조건 fully-connected 다. 따라서 만약 동일한 노드에서 동일한 인풋 엣지를 갖는다면 연산은 동일하므로 파라메터가 공유된다. 위 그림에서 3번 노드는 ReLU 를 사용하며 2번 노드를 input node 로 갖는데, 이 부분만 동일하다면 다른 부분이 싹 달라져도 파라메터를 공유한다는 것이다.
위 DAG 구조는 단순히 예를 위해서 든 것이 아니라 실제로 ENAS 에서 새로이 제안한 search space representation 이다. 위 설명에서 언급하지 않았지만 NASRL 은 RNN cell 을 찾을 때 LSTM 의 구조를 차용한 tree topology 를 사용한다. ENAS 에서는 이러한 트리 구조를 DAG 로 변경함으로써 더욱 유연한 구조를 제안한다. DAG 는 RNN cell 뿐만이 아니라 CNN 에도 적용 될 수 있는데, DAG 구조를 사용하여 CNN 전체 구조를 찾는 것을 macro search 라 하고, TNAS 에서 제안한 방식을 micro search 라 한다. 논문에서는 두 방식을 비교하는데 micro search 의 성능이 더 좋다.
이 외에도 최대한 효율적으로 탐색을 하기 위해 몇 가지 추가적인 아이디어가 도입된다. NASRL/TNAS 에서는 RNN controller 가 mini-batch 단위로 네트워크 구조를 생성하고, 그 구조들을 전부 학습한 뒤에 업데이트한다. ENAS 에서는 RNN controller 가 생성한 네트워크 구조들을 1-step 씩만 학습시켜 성능을 비교하고 제일 좋은 구조 하나만 학습한다. 또한 search space 도 극단적으로 줄였는데, 심지어 3x3 convolution 조차 search space 에 없다 (micro search 의 경우).
MNAS
MNAS 는 지금까지의 방법들과 목표가 다르다. 모바일에 적용가능한 NAS 를 찾는 것이 목표. 지금까지 살펴본 (그리고 앞으로 살펴볼) NAS 들은 전부 validation accuracy 를 objective function 으로 두고 이를 최적화하는 것을 목표로 한다. 그러나 모바일 세팅에서는 네트워크의 정확도를 조금 희생하더라도 가벼운 네트워크를 만드는 것이 매우 중요하다. 이렇게 모바일 환경에서 잘 작동하는 가벼운 네트워크를 찾는 것은 image classification 분야 안에서 새로운 하나의 분야를 이루고 있으며, 대표적으로는 MobileNet, ShuffleNet 시리즈들이 있다.
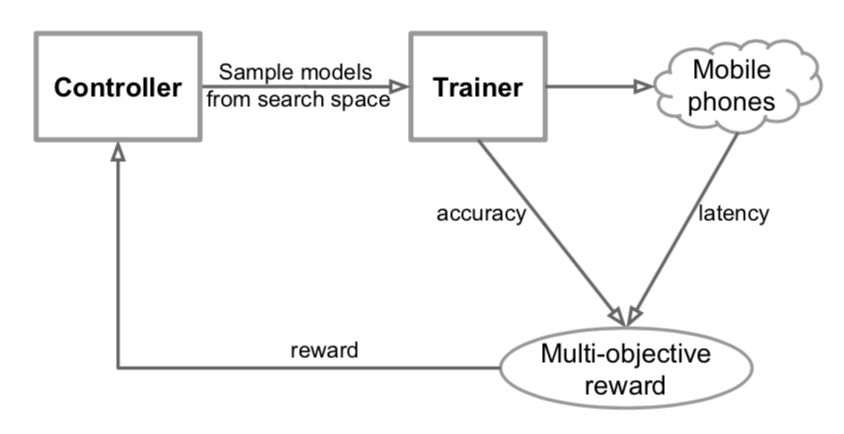
목표가 그렇다면 적용은 어렵지 않다. Reward 에 validation accuracy 뿐만이 아니라 latency (inference speed) 를 추가하여 최적화하면 된다. MNAS 이전에도 이러한 논문들이 있었으나, MNAS 에서는 latency constraint 를 soft 하게 걸어줌으로써 성능을 높이고 여러 latency 에 대한 Pareto optimal 을 찾을 수 있게 하였다.
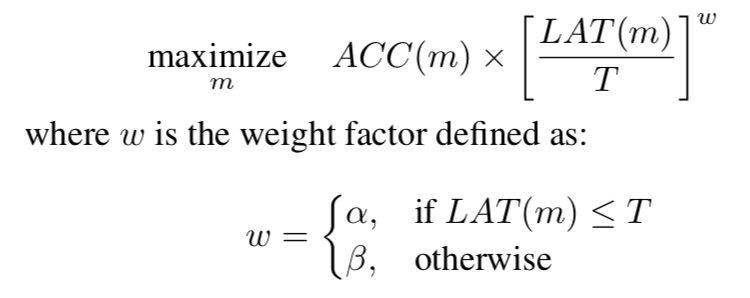
이전 연구들에서는 latency 에 대한 제한을 $LAT(m) \le T$ 와 같이 항상 T 보다 작거나 같도록 hard constraint 를 걸어주었지만, MNAS 에서는 위와 같이 soft constraint 로 변형하였다.
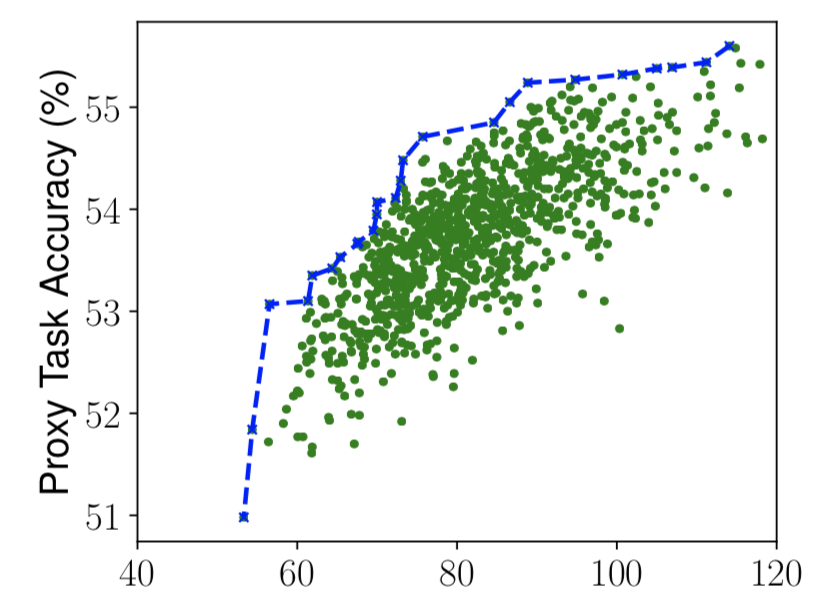
그 결과 위와 같은 Pareto optimal 을 얻을 수 있다. 가로축이 latency 로, 한번의 탐색으로 60 ~ 110 ms 의 latency 에 대해 각각 최적화된 구조를 찾을 수 있다.
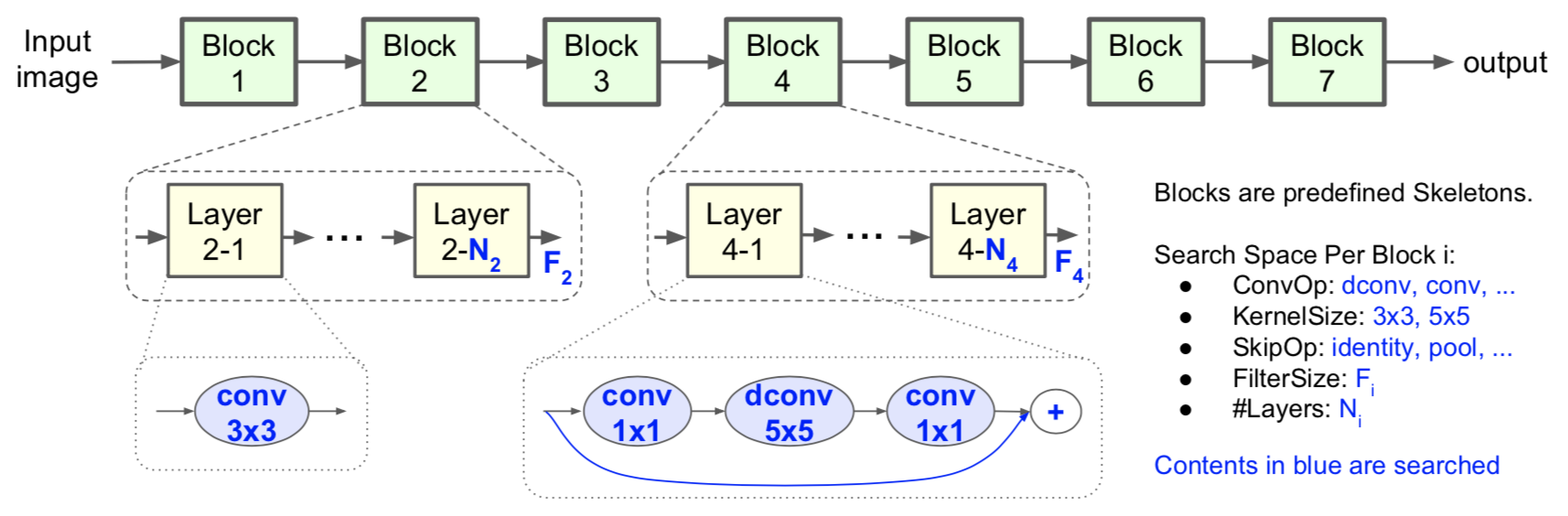
뿐만 아니라 MNAS 에서는 search space 도 새롭게 제안하는데, TNAS 에서 제안한 셀 구조를 찾아서 동일한 셀을 스택하는 방식을 따르는 것이 아니라, 모든 셀의 구조를 다르게 가져간다. 다만, 각 셀은 연산 하나로 정의되며 동일한 연산을 여러개 스택하여 하나의 셀을 이룬다. 그림에서 Block 2 는 3x3 conv 연산을 사용하는데, 그러면 Block 2 의 모든 레이어는 3x3 conv 가 되는 것이다. 조금 아쉬운 것은 이렇게 새로이 제안한 search space 에 대한 justification 이 없는 것인데, 논문에서 TNAS 의 셀 스택 구조와 비교 실험은 수행하지 않았다.
이 논문의 재미있는 insight 중 하나는 5x5 depthwise separable conv 에 있다. MNAS 에서 최종적으로 찾아낸 구조는 5x5 depthwise separable conv 를 사용하는데, 일반적으로 5x5 conv 는 3x3 conv 2개로 대체될 수 있기 때문에 잘 사용하지 않는다. 그러나 depthwise separable conv 에서는 5x5 하나가 3x3 2개보다 적은 연산량을 가진다.
Evolutionary Algorithms
사실 “네트워크 구조를 자동으로 찾아주는 알고리즘” 이라고 하면 바로 처음 떠오르는 방법이 아마도 EA 일 것이다. EA 는 있는 그대로 NAS 에 들어맞는다. 때문에 EA 로 NAS 를 수행하는 연구는 NeuroEvolution 이라고 불리며 오래된 역사를 갖고 있다.

위 알고리즘은 AmeobaNet 논문의 알고리즘이다. EA 를 알고 있다면, 위 알고리즘을 찬찬히 보면 대충 어떤 방식인지 알 수 있다 (사실 별 게 없다). Population 에서 랜덤 샘플링을 해서 좋은 모델은 mutation 을 거쳐 새로이 population 에 추가되고, 안 좋은 모델은 제거된다.
AmeobaNet
위 설명과 알고리즘이 안 맞는 부분이 있다. 샘플된 모델들 중에서 안 좋은 모델이 제거된다고 했는데, 위 알고리즘에는 Oldest 라고 되어 있다. 이 논문에서는 이와 같이 worst 를 제거하는 것이 아니라 oldest 를 제거하는 regularized evolution (RE) 을 제안하였다.
그리고 그게 끝이다. 뭐 없다고 느낀다면 그게 맞다. 그래서인지, 아니면 처음부터 의도가 그랬는지는 모르겠지만, 이 논문의 메인 컨트리뷰션은 새로운 방법의 제안이 아니라 EA 가 RL 보다 좋다는 것을 실험적으로 보였다는 데에 있다.
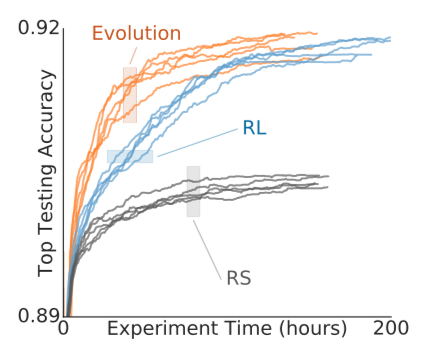
위 그래프에서 볼 수 있다시피 EA 가 RL 보다 더 빨리 수렴한다. 다만 최종 성능은 비슷하다고 한다. 애매한 컨트리뷰션 때문에 accept 이 잘 안된 것인지, 아카이브에 현재 버전 6으로 초기 버전에 비하면 상당히 많이 수정되었다.
Bayesian optimization
그런데 이 쯤에서 생각해 볼 것이 하나 있다. 왜 최적화 문제를 푸는데 우리에게 가장 친숙한 gradient descent 를 사용하지 않고 엄한 RL 이니 EA 니 들먹이고 있는가? 그건 우리의 objective function 이 non-differentiable 하기 때문이다. 그 때문에 최적화를 위해 gradient-based method 를 사용할 수 없고, non-differentiable objective 에 적용가능한 알고리즘인 RL 과 EA 가 나온 것이다. 그렇다면 이 맥락에서 빠질 수 없는 것이 Bayesian optimization (BO) 다.
AutoKeras
이 BO 를 사용한 논문이 바로 AutoKeras 가 나온 “Efficient neural architecture search with network morphism” 이다. 먼저 논문의 이름을 잘 보면 network morphism 이라는 단어가 나오는데, 이건 현재 네트워크의 지식을 유지하면서 네트워크의 구조를 바꾸는 방법이다. 즉, 학습된 네트워크의 구조를 바꾸면서도 동일한 input 에 대해 동일한 output 이 나오도록 유지한다는 것이다. 이는 위에서 언급한 4가지 연구 방향 중 4번에 해당하는데, objective function 을 계산하기 위한 비용이 너무 크기 때문에 학습된 네트워크의 지식을 유지함으로써 보다 빠르게 계산하기 위해서 사용된다. 즉 새로운 네트워크 아키텍처를 생성했을 때, 원래 이 네트워크 구조의 objective function 을 계산하려면 학습 후 validation accuracy 를 계산해야 하지만, network morphism 을 통하면 이미 상당 수준의 학습이 된 녀석이 나오기 때문에 약간만 추가 학습하여 objective function 을 계산할 수 있다. 이러한 network morphism 방식은 여기서만 사용되는 것이 아니며 objective function 을 빠르게 계산하기 위해 NAS에서 종종 사용된다.
자, 그럼 이제 BO 를 하면 된다! 그런데 이를 위해 필요한 것이 몇 가지 있다. 가장 먼저 kernel function 을 정의해야 한다. NAS 의 search space 가 Euclidean space 가 아니기 때문에 이에 맞는 커널 펑션을 새로이 정의해야 한다. 이 논문에서는 이 커널 펑션을 두 네트워크의 구조 간 edit distance 로 정의한다. 그 다음이 acquisition function 인데, 여기서는 UCB 를 사용하면서 새로이 정의한 search space 에 맞는 학습 방법을 제안한다.
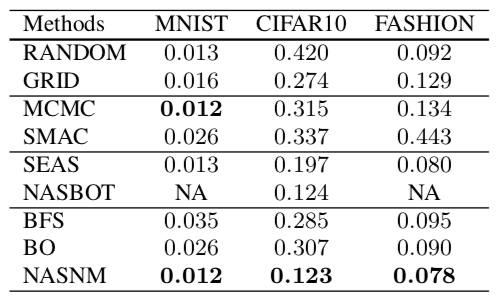
이 논문은 AutoKeras 로 꽤나 화제가 되었지만 논문의 결과는 사실 그렇게 인상적이지 않다. 위 수치 자체도 그다지 좋지 않으며, 비교 대상으로 선정한 방법들도 SOTA 들이 아니다. 브랜딩을 잘 한 논문으로 보인다.
Sequential Model-Based Optimization
Bayesian optimization 의 덩치가 크기 때문에 굳이 나누어 놓았지만, 사실 BO 는 Sequential Model-Based Optimization (SMBO) 의 일종이다. Model-based optimization 이란 최적화를 할 때 실제 값을 관측하는 비용을 줄이고자 실제 값을 예측하는 모델을 학습하는 방법이다. SMBO 는 여기서 모델을 학습하고, 학습한 모델에 기반하여 새로운 데이터를 얻는 과정을 iterative 하게 반복한다.
이를 NAS 에 적용해보자. 모델의 구조를 보고 성능을 예측하는 surrogate model 이 있다고 하면,
- 모든 가능한 구조들에 대해 성능을 예측해보고, 결과가 좋을 것 같은 구조를 고른다.
- 고른 구조들로 실제로 학습해서 결과를 본다.
- 새로 생긴 데이터들로 surrogate model 을 추가 학습한다.
이 과정을 반복하면 된다. 여기서 surrogate model 로 Gaussian process (GP) model 을 사용하면 Bayesian optimization 이 되는 것이다.
PNAS
PNAS 는 Progressive NAS 로, 블럭 크기를 작게 시작하여 점차 키워나가는 방식을 사용한다. Search space representation 은 TNAS 의 것을 가져오며, 다만 TNAS 의 서치 과정에서 사용되지 않은 연산들은 일부 제거한다. 또한 normal cell 과 피처맵 사이즈를 줄이는 reduction cell 을 따로 찾았던 TNAS 와는 달리, PNAS 에서는 normal cell 하나만 찾고 stride 를 조정하여 reduction cell 로 사용한다.
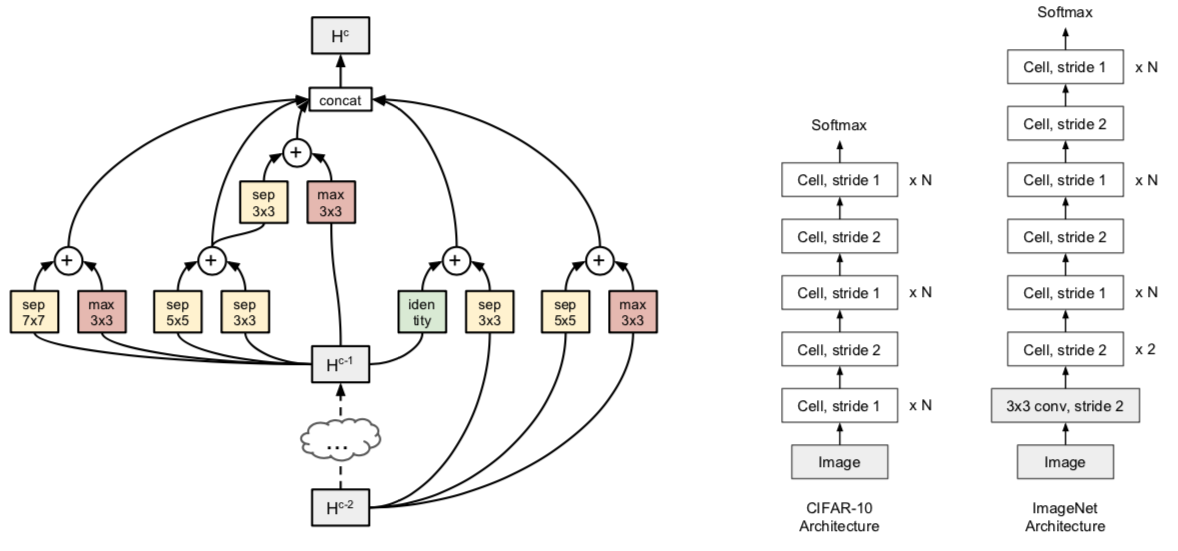
위와 같이 TNAS 와 동일하게 블럭 5개를 모아서 셀을 만들고, 셀을 스택하여 네트워크를 만든다. 작은 데이터셋에서 셀을 찾아서 큰 데이터셋에 적용하는 것도 동일하다. PNAS 는 여기에 더해 학습 속도를 빠르게 하기 위해 progressive 한 방식을 도입한다. RNN controller 를 사용하고 이를 RL 로 학습했던 TNAS 와는 달리, 작은 셀 구조에서 시작하여 모든 구조의 성능을 측정하면서 좋은 놈들만 남겨가며 점차 셀의 크기를 키우는 방식을 사용한다.

복잡해 보이지만 간단하다. 실제로 모든 구조를 다 학습시켜서 성능을 측정하는 것은 너무 큰 비용이 들어가므로, 네트워크 구조를 보고 학습 후의 성능을 예측하는 surrogate function 을 사용한다.
- b=1 (블럭 개수 1개) 에 대해 모든 구조를 다 만들어서 학습 후 surrogate function 학습
- b=2 로 블럭 개수를 증가시켜서 모든 구조를 다 생성한 후 surrogate function 을 통해 top-k 필터링
- 고른 구조들을 학습시켜서 실제 성능을 측정하고 이 데이터로 다시 surrogate function 학습
- b가 원하는 크기가 될 때까지 2~3 반복.
PNAS 는 이러한 방식으로 수천에 달했던 gpu days 를 수백까지 줄이는데 성공한다. 물론 위에서 언급한 ENAS 나 앞으로 설명할 DARTS 보다는 훨씬 큰 수치지만, 글 작성 순서 상 뒤에 있을 뿐 PNAS 가 먼저 나온 논문이라는 점을 잊지 말자.
Gradient descent
지금까지 계속 non-differentiable objective function 을 최적화하기 위해 gradient 를 사용하지 않는 방법들을 적용했다. 하지만 그게 아니라 objective function 을 변형해서 differentiable 하게 바꿀 수도 있지 않을까? DARTS 가 바로 그런 논문이다! 가장 인상적으로 읽은 논문이었기에 앞으로 3개의 포스트에 걸쳐 자세히 소개한다.
Related works
AutoML 에 대한 한국어 리뷰들은 아래에서도 찾아볼 수 있다. 여기서는 간단히 논문의 컨셉만 소개하였으니 좀 더 자세한 내용이 궁금하다면 논문과 아래 페이지들을 참조하자. 특히 OpenResearch 에서는 여기서 다루지 않는 논문들도 다루고 있다.