Khanrc
AutoML (5) - DARTS: multi-gpu extension
Multi-GPU Extention
본 포스트에서는 DARTS 구현의 multi-gpu 로의 확장을 다룬다. 이 내용의 최종 구현체는 https://github.com/khanrc/pt.darts 에서 확인할 수 있으며, Tutorial post 는 0.1 version 을 기반으로 하고 본 포스트는 0.2 verson 을 기반으로 한다.
공식 구현체의 이슈란에 보면 multi-gpu 로의 확장이 어렵다고 되어 있지만, 사실 그다지 어렵지 않게 확장이 가능하다. 거의 모든 multi-gpu training 은 data parallelism 방식이다. Data parallelism 은 input 을 나누어 각 gpu 로 보내고, 각 gpu 에서는 forward/backward 를 통해 gradient 를 계산한 후 이를 통합하여 weight 를 업데이트하는 과정으로 구성된다. 이게 가능한 이유는 대부분의 딥러닝 알고리즘은 각 데이터 포인트의 gradient 가 다른 데이터 포인트에 독립적으로 계산되기 때문으로, 이 조건만 만족한다면 data parallelism 을 적용할 수 있다. 그리고 DARTS 는 이 조건을 만족하기 때문에 data parallelism 으로 multi-gpu 적용이 가능하다.
Understanding multi-gpu module in pytorch
pytorch 에서는 multi-gpu 모듈로 nn.DataParallel 을 제공하고, 동일한 기능의 함수로 nn.parallel.data_parallel 함수를 제공한다. 이 구현을 간단히 살펴보자. 아래 코드는 전체 data_parallel 함수에서 중요하지 않은 예외처리 코드들을 걷어내었다.
def data_parallel(module, inputs, device_ids=None, output_device=None, dim=0, module_kwargs=None):
# 입력을 나누어 각 gpu 로 뿌림
inputs, module_kwargs = scatter_kwargs(inputs, module_kwargs, device_ids, dim)
# 각 gpu 마다 module 복제
replicas = replicate(module, device_ids)
# 이제 각 gpu 마다 input 과 module 이 있으니 forward 수행
outputs = parallel_apply(replicas, inputs, module_kwargs, device_ids)
# 연산 결과를 gather 함수로 통합
return gather(outputs, output_device, dim)
주석으로도 달아 놓았지만, data parallelism 은 아래와 같이 구성된다:
- Scatter: 전체 입력을 각 gpu 로 나누어 뿌림. batch size = 1024 / #gpu = 8 이라면, 각 gpu 마다 batch size = 128 로 나뉘어 뿌려진다.
- Replicate: 모듈을 각 gpu 로 복제. 보통 네트워크의 파라메터 사이즈가 매우 크기 때문에 이 과정이 상당히 무겁다.
- Parallel apply: 이제 각 gpu 는 모듈과 입력을 갖고 있으므로 forward 를 수행한다.
- Gather: forward 결과를 하나의 gpu 로 모은다.
위 설명은 forward pass 에 해당하고, backward pass 는 이 과정을 거꾸로 따라가면 된다. 각 gpu 는 loss 에 대해 gradient 를 계산하고, 계산된 gradient 는 다시 하나의 gpu 로 모아져서 weights 를 업데이트한다. BERT 의 구현으로 유명한 huggingface 팀에서 만든 좋은 피규어가 있어서 소개한다:
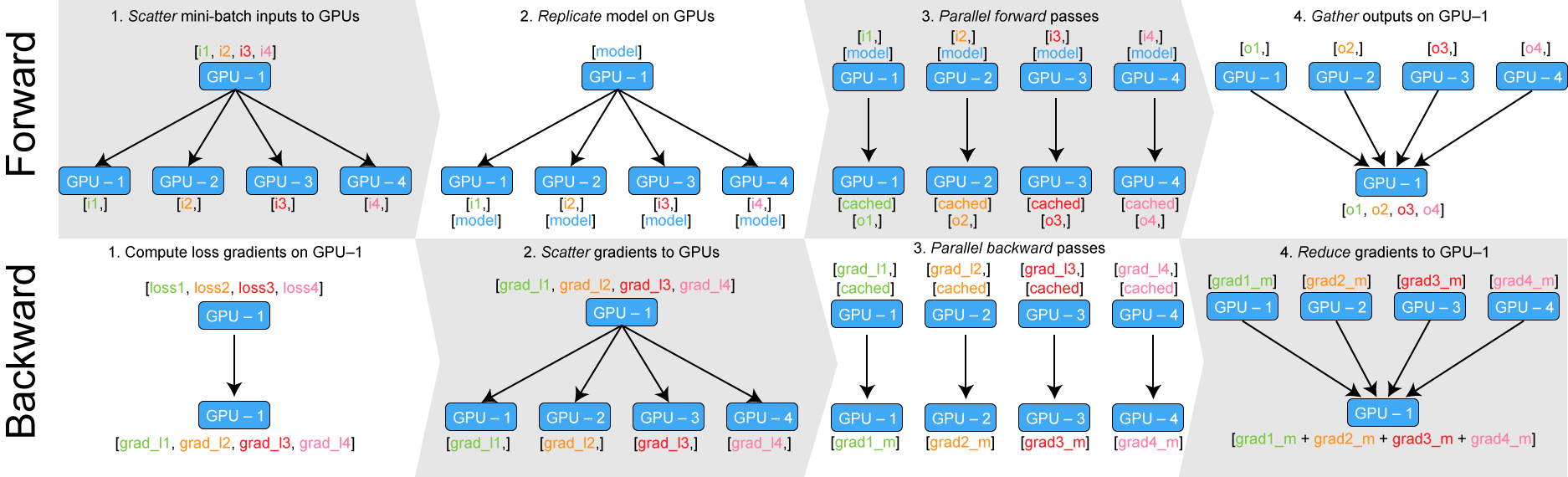
한걸음 더 들어가자면, 위 설명에서 파라메터를 각 gpu 마다 복제하고, 다시 각 gpu 의 gradient 를 하나의 gpu 로 모으는 과정이 data parallelism 에서의 병목 구간이 된다. 이 문제를 해결하기 위해 pytorch 는 Baidu 에서 제안한 ring-allreduce 알고리즘을 Nvidia 에서 구현한 NCCL (Nvidia Collective Communications Library) 을 사용한다. TensorFlow 등의 다른 라이브러리에서도 multi-gpu 를 직접 구현할 때 이 부분을 신경써주지 않으면 원하는 퍼포먼스가 나오지 않는다.
Ring-allreduce 알고리즘이 궁금하다면 Nvidia 의 발표 슬라이드 를 참고하자.
딥러닝에서 (거의) 모든 multi-gpu data parallelism 은 디테일한 부분을 제외하면 전부 위와 같은 알고리즘으로 구성된다. 단, single machine multi-gpu training 이 아니라 multi machine distributed training 이 되면 gpu 간 communication cost 가 더 커지게 되면서 asynchronous training 등도 고려사항이 된다.
Multi-GPU on Augment
Augment 페이즈에서 nn.DataParallel 을 사용하여 multi-gpu 를 구현하면 에러가 나는 것을 볼 수 있는데, 이는 단순히 우리 모듈에 커스텀 메소드들이 추가되었기 때문이다. 예를 들어 AugmentCNN 모듈을 DataParallel 모듈로 감싸게 되면 AugmentCNN 모듈이 갖고 있는 메소드로 바로 접근이 되지 않기 때문에 에러가 발생한다. 이 문제를 해결하기 위한 가장 간단한 방법은 DataParallel 모듈이 멤버 변수로 들고 있는 AugmentCNN 모듈에 접근해서 함수를 사용하는 것이다.
# https://github.com/khanrc/pt.darts/blob/0.2/augment.py
model = AugmentCNN(input_size, input_channels, config.init_channels, n_classes, config.layers,
use_aux, config.genotype)
model = nn.DataParallel(model, device_ids=config.gpus).to(device)
...
# training loop
for epoch in range(config.epochs):
lr_scheduler.step()
drop_prob = config.drop_path_prob * epoch / config.epochs
# model.drop_path_prob => model.module.drop_path_prob
model.module.drop_path_prob(drop_prob)
위와 같이 그냥 nn.DataParallel 모듈을 사용하면 되는데, 이 경우 AugmentCNN 모듈이 갖고 있는 drop_path_prob 메소드에 바로 접근이 안 되므로 model.module.drop_path_prob 으로 접근하여야 한다.
Multi-GPU on Search
Search 에서도 위와 같은 방식으로 문제 해결이 가능하다. 다만 커스텀 메소드가 하나만 추가되어 수정이 어렵지 않았던 augment 케이스와는 달리, search 에서는 커스텀 메소드도 여러개가 추가되었고 사용하는 곳도 여러 곳이라서 위와 같은 방식으로는 수정이 다소 지저분하게 된다. 따라서 사용하는 곳에서는 코드를 그대로 유지할 수 있도록 수정해 보자.
가장 쉽게는 SearchCNN 의 래퍼 (wrapper) 클래스를 작성하고 커스텀 메소드들에 대한 프록시 메소드들을 구현하여 간단히 구현할 수 있지만, 이왕 수정하는 김에 보다 좋은 구조로 구현해보자. alpha 와 weights (네트워크 파라메터) 를 모두 SearchCNN 에서 관리하던 기존 구조를 수정하여 SearchCNN 에서는 일반적인 네트워크처럼 weights 만 관리하도록 하고, SearchCNNController 를 만들어서 alpha 를 관리하도록 하자. SearchCNNController 는 SearchCNN 을 내부적으로 들고 있으면서 forward 시에 사용한다.
SearchCNN
기존에는 forward 시 내부적으로 들고 있는 alpha 로부터 각 연산의 가중치 weights 를 계산하였지만, 이제는 SearchCNN 이 alpha 를 직접 관리하지 않으므로 가중치 weights 를 입력으로 받는다.
# https://github.com/khanrc/pt.darts/blob/0.2/models/search_cnn.py
class SearchCNN(nn.Module):
def forward(self, x, weights_normal, weights_reduce):
s0 = s1 = self.stem(x)
for cell in self.cells:
weights = weights_reduce if cell.reduction else weights_normal
s0, s1 = s1, cell(s0, s1, weights)
out = self.gap(s1)
out = out.view(out.size(0), -1) # flatten
logits = self.linear(out)
return logits
위 링크의 전체 코드를 확인해보면, SearchCNN 의 코드가 간단해진 것을 확인할 수 있다. alpha 를 생성하고 관리하던 부분을 비롯하여 loss 를 계산하는 부분 등 여러 커스텀 메소드들을 SearchCNNController 로 넘겼기 때문이다.
주의) 위 코드에서의 weights 는 각 연산의 가중치로, 네트워크 파라메터를 가리키는 weights 와 구분하자.
SearchCNNController
먼저 alpha 의 생성 및 관리, loss 계산, genotype 변환 등의 메소드들을 추가해주자.
# https://github.com/khanrc/pt.darts/blob/0.2/models/search_cnn.py
class SearchCNNController(nn.Module):
""" SearchCNN controller supporting multi-gpu """
def __init__(self, C_in, C, n_classes, n_layers, criterion, n_nodes=4, stem_multiplier=3,
device_ids=None):
super().__init__()
self.n_nodes = n_nodes
self.criterion = criterion
if device_ids is None:
device_ids = list(range(torch.cuda.device_count()))
self.device_ids = device_ids
# initialize architect parameters: alphas
n_ops = len(gt.PRIMITIVES)
self.alpha_normal = nn.ParameterList()
self.alpha_reduce = nn.ParameterList()
for i in range(n_nodes):
self.alpha_normal.append(nn.Parameter(1e-3*torch.randn(i+2, n_ops)))
self.alpha_reduce.append(nn.Parameter(1e-3*torch.randn(i+2, n_ops)))
# setup alphas list
self._alphas = []
for n, p in self.named_parameters():
if 'alpha' in n:
self._alphas.append((n, p))
self.net = SearchCNN(C_in, C, n_classes, n_layers, n_nodes, stem_multiplier)
def forward(self, x):
...
def loss(self, X, y):
logits = self.forward(X)
return self.criterion(logits, y)
def print_alphas(self, logger):
# remove formats
org_formatters = []
for handler in logger.handlers:
org_formatters.append(handler.formatter)
handler.setFormatter(logging.Formatter("%(message)s"))
logger.info("####### ALPHA #######")
logger.info("# Alpha - normal")
for alpha in self.alpha_normal:
logger.info(F.softmax(alpha, dim=-1))
logger.info("\n# Alpha - reduce")
for alpha in self.alpha_reduce:
logger.info(F.softmax(alpha, dim=-1))
logger.info("#####################")
# restore formats
for handler, formatter in zip(logger.handlers, org_formatters):
handler.setFormatter(formatter)
def genotype(self):
gene_normal = gt.parse(self.alpha_normal, k=2)
gene_reduce = gt.parse(self.alpha_reduce, k=2)
concat = range(2, 2+self.n_nodes) # concat all intermediate nodes
return gt.Genotype(normal=gene_normal, normal_concat=concat,
reduce=gene_reduce, reduce_concat=concat)
def weights(self):
return self.net.parameters()
def named_weights(self):
return self.net.named_parameters()
def alphas(self):
for n, p in self._alphas:
yield p
def named_alphas(self):
for n, p in self._alphas:
yield n, p
디테일하게는 조금씩 달라진 부분이 있지만 기존 코드와 거의 동일하다. alpha 이터레이션을 조금이라도 빠르게 하기 위해서 내부적으로 _alphas 를 관리하고, alphas 를 출력하는 print_alphas 메소드에서 기존과 달리 로거를 사용하는 부분이 달라졌다. SearchCNNController 에서 기존과 가장 달라진 부분은 사실 위에서는 생략된 forward 메소드다.
# https://github.com/khanrc/pt.darts/blob/0.2/models/search_cnn.py
from torch.nn.parallel._functions import Broadcast
def broadcast_list(l, device_ids):
""" Broadcasting list """
l_copies = Broadcast.apply(device_ids, *l)
l_copies = [l_copies[i:i+len(l)] for i in range(0, len(l_copies), len(l))]
return l_copies
class SearchCNNController(nn.Module):
def forward(self, x):
weights_normal = [F.softmax(alpha, dim=-1) for alpha in self.alpha_normal]
weights_reduce = [F.softmax(alpha, dim=-1) for alpha in self.alpha_reduce]
if len(self.device_ids) == 1:
return self.net(x, weights_normal, weights_reduce)
# scatter x
xs = nn.parallel.scatter(x, self.device_ids)
# broadcast weights
wnormal_copies = broadcast_list(weights_normal, self.device_ids)
wreduce_copies = broadcast_list(weights_reduce, self.device_ids)
# replicate modules
replicas = nn.parallel.replicate(self.net, self.device_ids)
outputs = nn.parallel.parallel_apply(replicas,
list(zip(xs, wnormal_copies, wreduce_copies)),
devices=self.device_ids)
return nn.parallel.gather(outputs, self.device_ids[0])
위에서 설명했던 것과 동일한 data parallelism 코드지만, broadcast_list 라는 함수가 새로 등장한다. 이 함수는 alpha 로부터 계산한 연산 가중치 weights 들을 각 gpu 로 복제하여 뿌리기 위함인데, 입력을 gpu 마다 잘라서 보내는 scatter 함수로는 이 작업을 수행할 수가 없다. 처음부터 nn.DataParallel 모듈을 사용하지 않은 것도 이러한 이유로, DataParallel 모듈은 모든 입력을 scatter 로 처리하기 때문에 broadcasting 이 불가능하다. 따라서 data parallism 을 직접 구현하고, 데이터를 각 gpu 로 복제해주는 nn.parallel._functions.Broadcast 클래스를 사용하자. broadcast_list 함수는 이 Broadcast 클래스를 사용하여 list 의 broadcasting 을 구현하였다. 이외에 나머지 구현은 위에서 살펴보았던 data_parallel 함수와 동일한 것을 확인할 수 있다.
Cautions
이제 multi-gpu 구현은 끝났지만, 사용하는 것은 여기서 끝이 아니다. Multi-gpu 를 사용할 때 주의하여야 할 점이 있다. Multi-gpu 를 100% 활용하기 위해서는 그만큼 batch size 를 늘려주어야 하는데, 이 경우 동일한 epoch 을 돈다고 하면 generalization 이 떨어진다는 것이 잘 알려져있다.
이러한 문제를 다루는 연구들이 다양하게 있는데, 그 중 대표적인 논문이 2017년 페이스북의 Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour 이다. 방법 자체는 어렵지 않으니 multi-gpu 를 사용한다면 고려해보자. 다만 이 방법이 DARTS 에 잘 적용될 것인지는 적용해 보기 전에는 확실히 알 수 없다.